Day 1 problems, Day 2 problems and solutions (both days) to the first day of the USA Mathematical Olympiad, 2012.
Alejandro at Knewton briefly explains item response theory, a method for scoring exams. (Say two students get 9 out of 10 on an exam; one misses the easiest question, one the hardest. Which one is better at what the exam tests?)
Nate Silver, of fivethirtyeight, has launched the 2012 presidential election forecast.
Tim Gowers asks How should mathematics be taught to non-mathematicians? The post is motivated by certain proposed changes to secondary education in the UK, to introduce courses in “Uses of Mathematics”, but most of the post is devoted to suggesting the sort of questions that students in such courses would be able to answer, and you don’t need to know anything about the UK education system to appreciate these.
A graph in a glass: a machine that turns the distributions of fruits mentioned on Twitter into smoothies. (I’d prefer a pie chart made of actual pie.)
Distributional footprints of deceptive product reviews. Some companies soliciting people to write fake reviews of their products get too greedy, and this can be detected.
High school kids are assholes. (Not the actual title, which is “friendship networks and social status”.) In brief: “In every network, without exception, we find that there exists a ranking of participants, from low to high, such that almost all unreciprocated friendships consist of a lower-ranked individual claiming friendship with a higher-ranked one.” Perhaps I’d have more to say if the subject if this paper were emotionally neutral, but I’m not in the mood to dredge up painful memories.
Jordan Ellenberg’s review of Alexander Masters’ Simon: The Genius in My Basement. I mentioned this book back in March in a weekly links post (in which I also mentioned Jordan!).
I’m looking for a job, in the SF Bay Area. See my linkedin profile.
 spellings:
spellings:




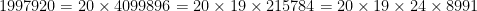
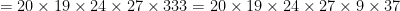
 to
to  in my decomposition of 58366440. I’ve already written
in my decomposition of 58366440. I’ve already written  . I know I’m going to have to write
. I know I’m going to have to write  as a product of four numbers, so they’re going to be near
as a product of four numbers, so they’re going to be near  . It turns out that
. It turns out that  is an integer, namely
is an integer, namely  , and no factor of
, and no factor of 
