From Deathsplanation, How tall is an alpaca? (and how long did people live in the past?)
From the Aperiodical, how to win at (the UK game show) Pointless.
Igor Pak has a collection of attempts to define combinatorics and a blog post on the subject.
From the MAA, some beautiful drawings of Platonic solids from the 16th-century printmaker Wenzel Jamnitzer.
From the Telegraph, Quants: the maths geniuses running Wall Street.
George Hart on making music with Mobius strips (following Dmitri Tymoczko).
Andrew Gelman and Kevin O’Rourke ask how statisticians pick their methods.
Carlos Futuri’s cartographical map projections.
OpenSignal on how phone batteries measure the weather (via Hacker News)
Hanging Hyena on unbeatable words in Hanging with Friends.
Emily Singer for Quanta magazine: In Natural Networks, Strength in Loops.
Hannah Fry on why everyone is more popular than you.
Jiri Matousek has a collection of Thirty-three miniatures: Mathematical and algorithmic applications of linear algebra
A Quora question, What kind of math do you use in your work?
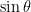 and
and 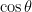 , for some angle
, for some angle  , and you need to figure out what
, and you need to figure out what 


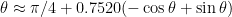 , in radians. In degrees this is
, in radians. In degrees this is  .
. — the smaller angle of a 5-12-13 right triangle. Then we get
— the smaller angle of a 5-12-13 right triangle. Then we get  . In fact
. In fact  — we’re not off by much! And the error is never more than a couple degrees, as you can see in the plot below.
— we’re not off by much! And the error is never more than a couple degrees, as you can see in the plot below.
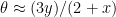
 . This is essentially a simplification of the rule that Ellenberg’s source (Hugh Worthington’s 1780 textbook, The Resolution of Triangles) gives, which can be translated into our notation as
. This is essentially a simplification of the rule that Ellenberg’s source (Hugh Worthington’s 1780 textbook, The Resolution of Triangles) gives, which can be translated into our notation as Applying this to our test angle with
Applying this to our test angle with  , we get
, we get  radians, while in truth
radians, while in truth  .
. is so nice that I can’t help but suspect there’s a simple derivation. Any takers?
is so nice that I can’t help but suspect there’s a simple derivation. Any takers? or about $2.2 \times 10^{22}$. Call this number
or about $2.2 \times 10^{22}$. Call this number  . And even that’s ignoring that you can make independent choices for the two halves of your pizza – so if we really wanted to inflate the number, there are
. And even that’s ignoring that you can make independent choices for the two halves of your pizza – so if we really wanted to inflate the number, there are  possible pizzas, where the
possible pizzas, where the  pizzas are just pairs of choices for the two halves. This is around
pizzas are just pairs of choices for the two halves. This is around  .
.