From the New York Times “Numberplay” blog:
An entrepreneur has devised a gambling machine that chooses two independent random variables x and y that are uniformly and independently distributed between 0 and 100. He plans to tell any customer the value of x and to ask him whether y > x or x > y.
If the customer guesses correctly, he is given y dollars. If x = y, he’s given y/2 dollars. And if he’s wrong about which is larger, he’s given nothing.
The entrepreneur plans to charge his customers $40 for the privilege of playing the game. Would you play?
Clearly the strategy is to guess that y > x if x is small, and to guess that y < x if x is large. Say you’re told x = 60. If you guess x is the larger variable, then conditional on your guess being correct (which has probability 0.6) you win an average of 30 dollars (halfway between 0 and 60). If your guess is incorrect you win nothing. Similarly, if you guess x is the smaller variable, then conditional on your guess being correct (which has probability 0.4) you win an average of 80 dollars (halfway between 60 and 100). So your expected winnings are 18 dollars if you guess x is the larger variable, and 32 if you guess x is the smaller variable. You should guess x is the smaller variable — that is, 60 is “small”.
This is surprising at first — 60 is closer to 100 than it is to 0, and if you’re just trying to guess correctly you’d guess that 60 was the larger of x and y. But the payoff is the unseen number y, and if x is the smaller variable then that biases the value of y upwards.
To simplify the analysis, I’m going to say that you’re given u and v, which are x/100 and y/100; so they’re uniformly distributed between 0 and 1. You’re told u, you get to guess if v is larger or smaller than u, and if you get it right you get 100v dollars.
You’re told u. If you guess u is the larger of the two variables, then conditional on your guess being correct — which has probability u — you win on average u/2 hundred dollars. And if you guess u is the smaller, then conditional on your guess being correct — which has probability 1-u — you win on average (1+u)/2 hundred dollars. So your expected winnings are  if you guess u is the larger, and
if you guess u is the larger, and  if you guess u is the smaller — all money is in units of one hundred dollars.
if you guess u is the smaller — all money is in units of one hundred dollars.
So you should guess u is the larger variable exactly when  ; that is, when
; that is, when  , or
, or  .
.
What is the expected payoff? It’s an easy integral, namely

and that’s about 0.4024 — the expected value of this game is $40.24. So you should play! But on the other hand the casino operator might still make money, because are people really going to sit down and work out the optimal strategy?
Lots of solutions were offered at the post giving the puzzle; Bayesian biologist had a simulation-based approach.
(Finally, you might notice that I ignored the possibility where x = y. That’s not because I’m forgetful, but because it happens with probability 0.)
 ?
?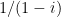 , right, by the usual formula for summing a geometric series? But this says that
, right, by the usual formula for summing a geometric series? But this says that
 . And
. And  , so it doesn’t work here. But who cares? Start taking partial sums. The sum is (after simplifying using
, so it doesn’t work here. But who cares? Start taking partial sums. The sum is (after simplifying using 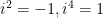 ):
):
 — and the average of this series is $(1+i)/2$, which is $1/(1-i)$. It’s a complex version of
— and the average of this series is $(1+i)/2$, which is $1/(1-i)$. It’s a complex version of  , and indeed the argument I’ve outlined here is
, and indeed the argument I’ve outlined here is 