There’s a restaurant in downtown San Francisco called ‘wichcraft. They make sandwiches.
This post is about their menu. Specifically, if you saw their menu could you work out the sales tax rate in effect?
It’s a silly question, at first. But consider their breakfast options. They cost, in descending order of price, $7.35, $6.90, $5.12, $4.68, $4.45, $4.01, $3.34, $2.45. (These are not the prices you’ll see on the menu at their web site, because their menu has their New York City prices.) These prices look a bit strange, but we might guess that they’re round numbers after tax. And in a US context, if you’re expecting cash transactions, “round numbers” means multiples of 25 cents.
Take the differences between these; they’re 45, 178, 44, 23, 44, 67, and 89 cents. Just looking at this sequence I can see some quantization; I guess that that 23-cent difference becomes a quarter after tax, the 44- and 45-cent differences become two quarters, and so on. So those differences are, in post-tax quarters, 2, 8, 2, 1, 2, 3, and 4, which add up to 22. In particular $2.45 becomes n quarters after tax, for some n, and $7.35 becomes 3n.
Then, $7.35 is three times $2.45; thus n is 11, and $2.45 pre-tax becomes $2.75 post-tax. The pre-tax prices, and the corresponding post-tax prices, are:
| $7.35 | $6.90 | $5.12 | $4.68 | $4.45 | $4.01 | $3.34 | $2.45 |
| $8.25 | $7.75 | $5.75 | $5.25 | $5.00 | $4.50 | $3.75 | $2.75 |
So what’s the tax rate? Each one of these prices gives us some small interval which contains the tax rate. Let the tax rate be x percent; then we must have, for example, that 7.35(1+x/100) is between 8.245 and 8.255, from which x must be between 12.177 and 12.313. We can do a similar computation for each price. The highest lower bound that we get is (4.995/4.45)-1 = 12.247 percent; the lowest upper bound is (5.255/4.68)-1 = 12.286 percent.
One last assumption – the tax rate is a round number. So it must be 12.25 percent.
But the California State Board of Equalization says the sales tax in San Francisco is 8.5 percent! And this is in conjunction with a couple places I saw on Clement Street a few weeks ago that charged $4.38 for a dim sum special, which are what inspired this post; add the tax and it’s $4.75 — I held this post back because from that single data point it’s hard to show much.
 , where
, where  is our best estimate of the quantity and
is our best estimate of the quantity and  is an estimate of the uncertainty. (We can think of this as being roughly the standard deviation of the distribution from which
is an estimate of the uncertainty. (We can think of this as being roughly the standard deviation of the distribution from which  – that is, the variances attached to the measurements add. Similarly, for differences,
– that is, the variances attached to the measurements add. Similarly, for differences,  . For example,
. For example, 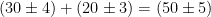 and
and 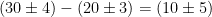 . Note that the error for the sum and the difference are the same – but for the difference, the error is relatively much bigger.
. Note that the error for the sum and the difference are the same – but for the difference, the error is relatively much bigger. , start by finding the fractional uncertainties
, start by finding the fractional uncertainties 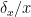 and
and  . Then the squares of the fractional uncertainties add: the fractional uncertainty of the product is
. Then the squares of the fractional uncertainties add: the fractional uncertainty of the product is  . The same fractional uncertainty holds for quotients. For example, the fractional uncertainty in
. The same fractional uncertainty holds for quotients. For example, the fractional uncertainty in  is
is 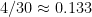 , and that in
, and that in  is
is 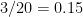 . So the fractional uncertainty in their product is $\sqrt{(0.133)^2 + (0.15)^2 = 0.201$. Thus we have for the product
. So the fractional uncertainty in their product is $\sqrt{(0.133)^2 + (0.15)^2 = 0.201$. Thus we have for the product  and for the quotient
and for the quotient  .
. .
. – in fact, when taking nth powers, the fractional uncertainty is raised to the
– in fact, when taking nth powers, the fractional uncertainty is raised to the  power. Similarly,
power. Similarly,
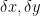 in the measurements of
in the measurements of 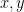 are independent! So these rules can’t be used if there’s correlation between the errors. More simply, they can’t be used if the quantity that you’re interested in is a function of many variables, some of which occur more than once. Consider for example the
are independent! So these rules can’t be used if there’s correlation between the errors. More simply, they can’t be used if the quantity that you’re interested in is a function of many variables, some of which occur more than once. Consider for example the  and
and  with
with 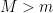 ; the larger mass accelerates downward, with acceleration
; the larger mass accelerates downward, with acceleration  . Here
. Here  is the acceleration due to gravity. We assume this is known exactly. So there may be correlation between the numerator and the denominator.
is the acceleration due to gravity. We assume this is known exactly. So there may be correlation between the numerator and the denominator.
 , and use the rules that I’ve already discussed. (But it may be hard to see that this is worth doing!) For example (I’m taking these numbers from Taylor) say
, and use the rules that I’ve already discussed. (But it may be hard to see that this is worth doing!) For example (I’m taking these numbers from Taylor) say  . Then the fractional uncertainty in the quotient
. Then the fractional uncertainty in the quotient  is
is , and we get
, and we get  . Then
. Then 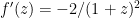 , so
, so  , and thus we have
, and thus we have  .
. is likely to lie in the interval
is likely to lie in the interval ![0.5 \pm 0.011 = [0.489, 0.511]](https://s0.wp.com/latex.php?latex=0.5+%5Cpm+0.011+%3D+%5B0.489%2C+0.511%5D&bg=ffffff&fg=000000&s=0&c=20201002) ; then f(0.489) = 0.343 and f(0.511) = 0.324, so we figure that f(m/M) is likely to lie in the interval [0.324, 0.343].
; then f(0.489) = 0.343 and f(0.511) = 0.324, so we figure that f(m/M) is likely to lie in the interval [0.324, 0.343].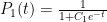

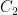 . Furthermore
. Furthermore  , where
, where 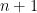 is the number of students; solving gives
is the number of students; solving gives  .
.
 denotes the odds of
denotes the odds of 
 denotes the event of not having heard yet. Typical pass rates at the time I was there were perhaps 3 out of 4, so
denotes the event of not having heard yet. Typical pass rates at the time I was there were perhaps 3 out of 4, so  . The conditional odds are therefore
. The conditional odds are therefore
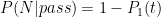 and
and  . So, after some algebra,
. So, after some algebra,
 . So the longer you go without hearing the news of someone’s exam outcome, the more likely it is that it’s bad news.
. So the longer you go without hearing the news of someone’s exam outcome, the more likely it is that it’s bad news. and
and  , and replace with
, and replace with  , where some possible choices of
, where some possible choices of  (
( (
( (
( (
( . And say we start with the numbers 2, 3, 6, 7. Then we could choose to do the replacement as follows. In each case the two bolded numbers are replaced by one.
. And say we start with the numbers 2, 3, 6, 7. Then we could choose to do the replacement as follows. In each case the two bolded numbers are replaced by one.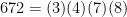 , which we can rewrite as
, which we can rewrite as
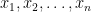 , as computing the product
, as computing the product  by combining two factors at a time; of course the order doesn’t matter.
by combining two factors at a time; of course the order doesn’t matter.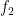 , if we start with
, if we start with  . With
. With 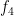 , we get
, we get  . The result with
. The result with  is a little harder to see but if we start with
is a little harder to see but if we start with 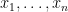 we eventually get
we eventually get 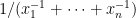 . This is a bit easier to see if we realize that
. This is a bit easier to see if we realize that  ; therefore applying
; therefore applying  and
and  ; iterating these functions will just give the sum or the product of the original numbers. But what other nontrivial examples are there? Can you say what all of them are?
; iterating these functions will just give the sum or the product of the original numbers. But what other nontrivial examples are there? Can you say what all of them are?
{kind=link}