Say I have two Poisson processes of constant density λ on the unit interval [0, 1]. What’s the probability that the maximum of the first process is greater than the minimum of the second? (For reasons to be explained later, I’ll stipulate that the maximum of no numbers is negative infinity, and the minimum of no numbers is positive infinity.) Call this probability f(λ).
To answer this question by simulation, we can first sample two indpendent random Poisson(λ) variables (which is kind of annoying), M and N; then sample independent uniform random variables  and
and 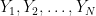 ; and finally check if
; and finally check if 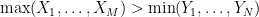 .
.
For example, with λ = 3 we might have M = 3, N = 2; then perhasp 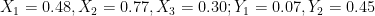 . The maximum of the
. The maximum of the  is 0.77, which is greater than the minimum of the
is 0.77, which is greater than the minimum of the 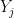 , 0.07.
, 0.07.
A few lines of R suffice to run, say, ten thousand simulations for any given λ (which should get us f(λ) to within one percent or so):
simulate = function(lambda, n) {
x = replicate(n, max(runif(rpois(1,lambda),0,1)));
y = replicate(n, min(runif(rpois(1,lambda),0,1)));
sum(x>y)/n
}
And from there we can generate data for a plot, say, by estimating f(λ) for λ = 0, 0.1, …, 6, with ten thousand simulations each:

An analytic solution is also possible, from standard facts about Poisson processes – the minimum of a density-λ Poisson process on [0, &infty;) is exponentially distributed with rate λ. Suitably modifying this for the fact that we’re dealing with [0,1] and sometimes with maxima, and doing some double integrals, it turns out that 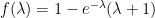 , the red line in the plot above.
, the red line in the plot above.
Finally, why would anyone care about this question? Imagine you run a web site, and on each comment you put a time stamp, and that time stamp is the time that it was at your server at the time the comment was made. Then say someone comes by at 1:45 AM Pacific Daylight Time this morning and leaves a comment, and someone else comes along at 1:15 AM Pacific Standard Time — which is actually a half-hour later — and leaves a comment. The comments will appear to be in the wrong order, like they do here. Then f(λ) is the probability of this occuring where λ is the number of comments per hour. Alternatively, it’s the probability that given just the sequence of timestamps in local time you can work out which are the last daylight-savings-time comment and the first standard-time comment. As I said here, this is an increasing function of λ, although I am not too lazy to work it out.

