Patrick Honner tweeted a few days ago:
Of course you could easily make a 300-piece puzzle, for example 15 by 20. And you could make a 299-piece puzzle — that factors as 13 times 23. But a 301-piece puzzle would have to be 7 by 43, assuming that the pieces form a nice grid,and that doesn’t seem like a “reasonable” size for a puzzle.
So which numbers could actually be reasonable sizes for puzzles? This could be nice to know if, say, you want to know if you have all the edge pieces. (But a 500-piece puzzle could be 20 x 25, or some reasonable slightly larger numbers like 19 x 27 = 513, or 18 x 28 = 504.) It’s a nice puzzle nonetheless.
So let’s say that a number is a “puzzle number” if it’s of the form  with
with 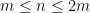 — that is, a puzzle has to have an aspect ratio between 1 (square) and 2. (The choice of 2 is arbitrary here, but any other constant would be more arbitrary.) We can easily work out the first few puzzle numbers:
— that is, a puzzle has to have an aspect ratio between 1 (square) and 2. (The choice of 2 is arbitrary here, but any other constant would be more arbitrary.) We can easily work out the first few puzzle numbers:
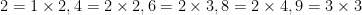
which is enough to find them in the OEIS: that’s A071562, defined as “Numbers n such that the sum of the middle divisors of n (A071090) is not zero.” (What’s a “middle divisor”, you ask? It’s a divisor of  that’s between
that’s between  and
and 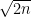 .) Titling it that way seems a bit strange to me: I’d have called it “Numbers such that the number of middle divisors of n (A067742) is nonzero”.
.) Titling it that way seems a bit strange to me: I’d have called it “Numbers such that the number of middle divisors of n (A067742) is nonzero”.
The first 10,000 puzzle numbers have been calculated; the 10,000th is 35,956. There are 43 under 100, 336 under 1,000, and 2,932 under 10,000 — it doesn’t appear that they have contant density. It’s not hard to take this further — there are 26870 under  , 252,756 under
, 252,756 under  , 2409731 under
, 2409731 under  , and 23169860 under
, and 23169860 under  . For example, in R, you can generate the puzzle numbers as follows. (This take a few seconds to run. Note that you don’t have to compute any prime factorizations.)
. For example, in R, you can generate the puzzle numbers as follows. (This take a few seconds to run. Note that you don’t have to compute any prime factorizations.)
N = 10^8
= rep(0, N)
for (m in 1:floor(sqrt(N))){
max_n = min(2*m,floor(N/m))
a[m*(m:max_n)] = a[m*(m:max_n)]+1
}
puzzle = which(a >= 1)
I had at first thought this sequence had a natural density, because I was only trying numbers up to a few hundred in my head, and because the number of middle divisors appears to average somewhere around  . There’s a nice heuristic for this – a middle divisor of is somewhere between and ; the “probability” that a number is divisible by
. There’s a nice heuristic for this – a middle divisor of is somewhere between and ; the “probability” that a number is divisible by  is
is  , so the “expected number” of middle divisors of is
, so the “expected number” of middle divisors of is
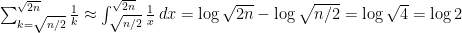 .
.
But there must be more numbers as you go further out that have many middle divisors, and more zeroes. This is similar to the behavior you see for the problem of “how many ways can an integer be written as a sum of two squares”. In that case the “average” is  , but an integer greater than one can be written as a sum of two squares if and only if its prime decomposition contains no prime congruent to 3 mod 4 raised to an odd power; asymptotically the number of positive integers below
, but an integer greater than one can be written as a sum of two squares if and only if its prime decomposition contains no prime congruent to 3 mod 4 raised to an odd power; asymptotically the number of positive integers below  which are the sum of two squares goes like
which are the sum of two squares goes like  for a constant
for a constant  (the constant is the Landau-Ramanujan constant). That connection might stem from the fact that both sequences are multiplicative. For sums of two squares, that follows from the factorization-based characterization or from the fact that
(the constant is the Landau-Ramanujan constant). That connection might stem from the fact that both sequences are multiplicative. For sums of two squares, that follows from the factorization-based characterization or from the fact that
 .
.
For puzzle numbers, it follows from a remark of Franklin T. Adams-Watters in the OEIS entry. So numbers which have lots of factors both tend to be sums of two squares and to be puzzle numbers in many different ways; as we get to bigger numbers those start “crowding out” the smaller numbers.
The math internet has noticed this at least once before. John D. Cook wrote in 2014: Jigsaw puzzles that say they have 1,000 pieces have approximately 1,000 pieces, but probably not exactly 1,000. Jigsaw puzzle pieces are typically arranged in a grid, so the number of pieces along a side has to be a divisor of the total number of pieces. This means there aren’t very many ways to make a puzzle with exactly 1,000 pieces, and most have awkward aspect ratios.
1000 as 25-by-40 seems reasonable, but 27 x 37 = 999 or 28 x 36 = 1008 would also work. I assume that you wouldn’t actually see a 999-piece puzzle because the lawyers would claim calling that 1000 was false advertising. A puzzle blog indicates that most “500-piece” puzzles are actually 27 x 19 = 513 and most “1000-piece” puzzles are 38 x 27 = 1026 – both of these aspect ratios are approximations of  . That is a good aspect ratio to use if you want the ability to make both “500-piece” and “1000-piece” (or more generally, “N-piece” and “2N-piece”) versions of the same puzzle. Similarly the A0, A1, … series of paper sizes used in most of the world have that aspect ratio and therefore an An piece of paper can be cut into two A(n+1) pieces.
. That is a good aspect ratio to use if you want the ability to make both “500-piece” and “1000-piece” (or more generally, “N-piece” and “2N-piece”) versions of the same puzzle. Similarly the A0, A1, … series of paper sizes used in most of the world have that aspect ratio and therefore an An piece of paper can be cut into two A(n+1) pieces.