A friend of mine got on a plane last night in San Francisco, at about 10:30 pm local time. She’s landing in Sydney at about 8:30 am local time on January 1. She asked: Does she get a New Year (i. e. is her local time ever midnight on December 31 / January 1)?
As far as I can tell, the answer is no. Here’s a map of the flight. The locations of the airports in question are:
SFO (37°37’08″N 122°22’31″W)
SYD (33°56’46″S 151°10’38″E)
`
The answer I gave was as follows: approximately speaking, she crosses over the date line about two-thirds of the way through the flight (since SFO is roughly 60 degrees east of the line and SYD is roughly 30 degrees west of it). It’s a fifteen-hour flight, so that’s ten hours in. At that time it’ll be 8:30 AM Dec 31 in San Francisco (UTC-8) so 4:30 AM Dec 31, UTC-12. At that time she crosses the line to 4:30 AM Jan 01, UTC+12 (which is 3:30 AM in Sydney, which is UTC+11 this time of year). So the answer to the question is yes.
(Note that I made the crude assumption that the date line is the 180th meridian, which it isn’t exactly. But the answer isn’t even close to depending on that.)
The flight in question is, I believe, United 863, which as of this writing hasn’t crosses the date line yet, but you can look at the tracking log for yesterday. The flight that left on the night of the 29th crossed the date line just around 11 AM US Eastern time (UTC-5) i. e. 4 AM UTC-12/UTC+12. The flight that left on the night of the 30th made that crossing around 12:41 PM US Eastern time, i. e. 5:41 AM at the 180th meridian. (The flight appears to have been closer to a great circle yesterday but took a more southerly route today, based on the FlightAware tracking pages here and here.) Coincidentally this is about when this post is going up.
In other Pacific Ocean time zone fun, there was no such day as December 31, 1844 in the Philippines. Their trade links had previously come from the east (the Americas) but as of that time had started coming more from the west (Asia).
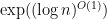 where
where  is the number of vertices, for those of you who don’t remember your complexity classes). The actual preprint is
is the number of vertices, for those of you who don’t remember your complexity classes). The actual preprint is with
with  , where each denominator is the product of three distinct primes. A footnote, on the obvious generalization to expressing rational numbers in such a form, reads:
, where each denominator is the product of three distinct primes. A footnote, on the obvious generalization to expressing rational numbers in such a form, reads: .
.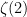 in his
in his 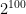 100-digit numbers composed only of the digits 4 and 9, and the chances that any given 100-digit number is divisible by
100-digit numbers composed only of the digits 4 and 9, and the chances that any given 100-digit number is divisible by 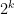 if the number made up of its last
if the number made up of its last  digits is divisible by
digits is divisible by  is the set of
is the set of  , etc. We’ll prove by induction that
, etc. We’ll prove by induction that  . Assume this is true for
. Assume this is true for  , we want to find
, we want to find  . Every number in
. Every number in  and
and  (that is, the numbers made from
(that is, the numbers made from 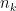 by writing
by writing  and
and  at the front). Now, since
at the front). Now, since  or
or  .
.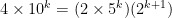 is a multiple of
is a multiple of  , And observe that
, And observe that  has exactly
has exactly 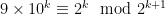 .
.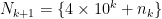 , and if
, and if 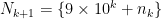 . In either case
. In either case 
{kind=link}