I would like to wish the R statistics software a happy third birthday.
Month: February 2012
Continued fraction day
Why do we have February 29 this year, and not in other years? Of course it’s because the ratio between the Earth’s orbital period and its rotational period is not an integer, but rather is about 365.242199. Let’s call this 365+α. And this is approximated well by the rational number 
Yury Grabovsky observes that the next few convergents to α are 7/29, 8/33, 31/128, 163/673, and indeed the Iranian calendar uses 8 leap years in 33. This is a bit harder to compute in one’s head. 31/128 would be pretty easy to work with — a year is a leap year if it’s divisible by 4, except not if it’s divisible by 128.
(Implicit in the Gregorian calendar rules — no leap years in years divisible by 100, except if they’re divisible by 400 — is the rational approximation 97/400, but that’s not a convergent.)
Therefore I nominate February 29 (in years when it occurs) as a new holiday, to be observed by the consumption and/or use of things that rely on rational approximations to irrational numbers.
What are these, you ask?
1. go look at the moon. The Metonic cycle is a period of 19 years, which is very nearly 235 (synodic) lunar months. So the full moon, for example, falls on (approximately) the same day on the solar calendar in the year N and in the year N + 19. The Hebrew calendar has seven leap years in nineteen, where the leap years have 13 (lunar) months instead of twelve. The Islamic calendar has twelve lunar months in each year, with the result that they fall backwards 
2. play some music. Western music theory is based on the existence of the circle of fifths, which in turn is based on the fact that $(3/2)12 \approx 2^7$ — that is, twelve perfect fifths is very nearly seven octaves. Taking logs this becomes $\log_2 3 \approx 19/12$. The fact that this is not the best approximation ever — it’s off by $0.0016$ — as well as the desire to incorporate other consonances into musical tuning caused lots of trouble.
3. use a computer. In computer world we use the prefix “kilo-” to stand for 1024 or 210, while everywhere else we use “kilo-” to stand for 1000 or 103. This abuse of language is only possible because 
4. it might be your birthday, in which case I am sad for you because your birthday comes but once every four years! But 253/365 is a convergent to 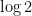
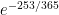
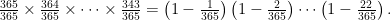
But if you remember that 


And the answer to the famous “birthday problem” — how many people do you have to have for there to be a fifty percent chance that two of them have the same birthday — is twenty-three.
(I honestly hadn’t seen this one until I was preparing for this week’s classes. It just so happens that the right day to introduce the birthday problem in one of my classes this semester is February 29… also, R has a command for this.)
5. if it’s your birthday, you should eat cake. If it’s not, you should eat pie. Of course the most famous rational approximation of them all is 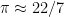
(It appears I’m not the first person to mention continued fractions on February 29. Mark Dominus did it in 2008, and I linked to it. Also, here’s an online continued fraction calculator. James Grime beat me to the punch, posting this Numberphile video with astronomer Meghan Gray; he posted while it was still February 28, despite being eight time zones ahead of me.
Why everyone thinks they’re above average, following Schelling
Thomas Schelling, in his fascinating book Micromotives and Macrobehavior (pp. 64-65 of the 2006 Norton edition) writes:
Ask people whether they consider themselves above or below average as drivers. Most people rank themselves above. When you tell them that, most of them smile sheepishly.
There are three possibilities. The average they have in mind is an arithmetic mean and if a minority drive badly enough a big majority can be “above average”. Or everybody ranks himself high in qualities he values: careful drivers give weight to care, skillfyl drivers give weight to skill, and those who think that, whatever sle they are not, at least they are polite, give weight to courtest, and come out high on their own scale. (Thsi is the way that every child has the best dog on the block.) Or some of us are kidding ourselves.
I’d long heard something similar in that “75 percent of students entering [insert elite college] think they’ll be in the top quarter of their class”; “top quarter” presumably means top quarter in GPA, so everybody is working on the same scale. But as Schelling points out, people probably judge driving on different scales. And I really don’t think people think intuitively in terms of means in the driving case; that requires doing arithmetic on numbers that don’t even exist.
So naturally I wondered how strong the effect is. Let’s assume that person 

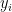
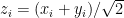
Now consider someone with, say, 

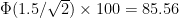
But now say this person perceives the world around them using a subjective score of the form 


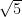


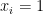


For a general person let 
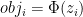
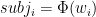

Here’s a scatterplot of 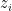
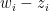

Here’s the distribution of people’s self-perceived ranks, from a simulation of ten thousand individuals. The histogram for objective ranks is nearly flat. The piling up near the right indicates that people are thinking more highly of themselves than would be objectively true. For a very quick measure, in this simulation of 10,000 individuals, 5,937 perceive themselves as above the median.

Here’s the distribution of “perception gaps”, the difference between subjective and objective ranks.

And somewhat surpisingly, about six percent of people have a lower subjective rank than objective rank. This is the “well-rounded” group that has both 

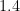

One expects this effect to be stronger if there are more factors to be considered; I’ll save that for another post.
Pythagoras goes linear
Let ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002)





x=runif(10^4,0,1)
y=runif(10^4,0,1)
w=rep(0,10^4); for(i in 1:10^4){w[i]=min(x[i],y[i])}
z=rep(0,10^4); for(i in 1:10^4){z[i]=max(x[i],y[i])}
h=sqrt(w^2+z^2)
lm(h~0+w+z)
to fit a linear model of the form 



appears to predict a as a linear function of 
Andrew Gelman and Deborah Nolan, in Teaching Statistics: A bag of tricks, give a very similar example, with slightly different numerical parameters and quip that “if Pythagoras knew about multiple regression, he might never have discovered his famous theorem”. (p. 146). They fit a model that is allowed to have nonzero constant term; I choose to fit a model with zero constant term. I think that our anachronistic Pythagoras would have had the sense to observe that if we double x and y, we should double the hypotenuse as well.
The natural question, to me, is to determine the “true” constants. So what constants a and B give the linear function 
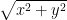
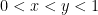
$f(a,b) = latex \int_0^1 \int_0^y \left( \sqrt{x^2+y^2} – (ax+by) \right)^2 \: dx \: dy $
as a function of a and b. This is a calculus problem. Expand the integrand to get
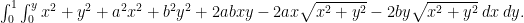
The polynomials are easy to integrate; the square-root terms somewhat less so, if it’s been a while since you’ve done freshman calculus. But after a bit of work this is
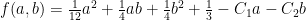
where 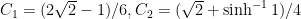

and

Set both of these equal to zero and solve to get

which are tolerably close to the coefficients that came out of the regression. (Those coefficients had standard errors of 0.0009 and 0.0005 respectively.)
Of course our hypothetical Pythagoras couldn’t have done these integrals, and would not have liked that they turn out to be irrational. Perhaps he would have just said that the length of the hypotenuse of a triangle was three-sevenths of the shorter leg, plus fourteen-fifteenths of the longer leg.
Weekly links for February 26
Robert Talbert on The origin of the nabla symbol.
Ivars Peterson observes that article titles make a difference. (This is part of a larger site on mathematical writing.)
A cute number-theoretic puzzle from John D. Cook.
The shortest route from every Hubway station to every other. Hubway is a bike-sharing system and all its stations are within the city of Boston, but not surprisingly some routes go through Cambridge or Brookline, because Boston is not convex.
From math.stackexchange, examples of apparent patterns than eventually fail.
From Social Flow, Timing, Network and Topicality: A Revealing Look at How Whitney Houston Death News Spread on Twitter. (There was a 42-minute period where the news had been tweeted but almost nobody knew about it.)
Piotr Blaszczyk, Mikhail G. Katz, David Sherry, Ten Misconceptions from the History of Analysis and Their Debunking.
Over the last decade, baby teeth are a better investment than the stock market.
Math doesn’t suck, you do. Interesting, but crass and offensive. The way to convince people that math is awesome is not to insult them.
Most 3-pixel-by-3-pixel=squares in black and white photos lie near a Klein bottle in a nine-dimensional space.
The Miura-Ori map folds itself. With animated gif.
Annie Keeghan, at Salon, writes Afraid of your child’s math textbook? You should be. Some interesting comments at Hacker News.
Pascal’s Triangle revisited?
Why is the last episode of the first season of Community called “Pascal’s Triangle Revisited”? I suppose it’s because it’s one of those season finales where couples break up and get back together, but that seems a bit forced.
An earlier episode includes a statistics professor who has a poster in her office labeled “know your graphs” in the background. Screen shots here and here.
Test design and grade inflation
I gave an exam yesterday. While I was standing in the copy room making copies, one of the grad students walked by.
“Midterms?”, he said.
“Yes,” I said.
“Grading’s not fun.”
“I hope this one won’t be too bad. Lots of questions with simple answers.”
“Yeah, you think that now, but it’s amazing what they come up with.”
“Sure. My trick is this. I used to write exams to be out of a hundred, and you’d end up with things worth six, eight, ten points and you sweat over partial credit. What’s the difference between a four and a five out of six? Now I write with questions being out of two or three, and I spend a lot less time thinking about that. If it’s out of two, zero is wrong, one is sort of right, two is entirely right or almost so. The grades come out just as accurate.”
The exam in question was out of thirty-six points, with three one-point items, nine two-pointers, and five three-pointers.
I’ve given this spiel before, ever since I discovered this trick. What I hadn’t realized is that it’s a smaller-scale version of Jordan Ellenberg’s take on grade inflation. Ellenberg argues that, first, if GPAs are to be used in order to discriminate between stronger and less strong students, what matters is not how high the grades are but how many different grades there are, so having a scale where the only grades used are A, A-, B+, B, B- is just as good as having a scale where the only grades used are A, B, C, D, F. And he gives the results of some calculations showing that if there are only three posssible grades — or even two, in some dystopian world where the only possible grades are A and A- — we still have some reasonable ability to discriminate between students over the course of an undergraduate career.
(Disclaimer: I’ve met Jordan. He’s also the cousin of a friend of mine I met through different channels. It’s a small world after all.)
An answer to a puzzle
The puzzle I posted a few days ago is derived from a puzzle that’s worked its way around the Internet every so often in the past few years. See this forum in Russian (why don’t I know Russian?), or Misha Lemeshko’s blog, or Daniel Lemire for the version that mine is derived from. The incarnation I saw on Wednesday, on Facebook, which inspired this post, says that “This problem can be solved by pre-school children in 5-10 minutes, by programmers – in 1 hour, by people with higher education… well, check it yourself! 🙂
It’s then followed by the following list of numbers:
8809 = 6
7111 = 0
2172 = 0
6666 = 4
1111 = 0
3213 = 0
7662 = 2
9312 = 1
0000 = 4
2222 = 0
3333 = 0
5555 = 0
8193 = 3
8096 = 5
7777 = 0
9999 = 4
7756 = 1
6855 = 3
9881 = 5
5531 = 0
2581 = ?
Sort of implicit in the hint is that maybe it has something to do with the digits; Real Mathematicians think that puzzles involving digits are somehow inferior. (In A Mathematician’s Apology Hardy observes of facts such as 8712 = 4 × 2178 and 153 = 13 + 5 3 + 33 that “[t]hese are odd facts, very suitable for puzzle columns and likely to amuse amateurs, but there is nothing in them which appeals much to a mathematician.”
Perhaps the natural thing to do, if this is a claim about digits, is to then assume that the claim 8809 = 6 encodes the statement 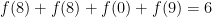


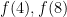
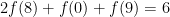

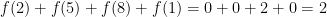
As for the version I gave — there are eight equations in nine unknowns. These were derived by removing from the “bloated” version of the puzzle all the equations with four of the same digits on the left side, and all those with a zero on the right side. The system again has equations 
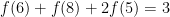
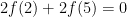



But what are the values of 0, 1, and 9? It turns out that either 
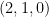
So why does 4 never appears on the left hand side, therefore meaning we can never work out 
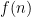


Paul Graham, generalizer
Paul Graham has an interesting essay entitled How to do what you love. It was posted on his web site in 2006, and this paragraph has stuck with me for years:
This test [would people do it for free?] is especially helpful in deciding between different kinds of academic work, because fields vary greatly in this respect. Most good mathematicians would work on math even if there were no jobs as math professors, whereas in the departments at the other end of the spectrum, the availability of teaching jobs is the driver: people would rather be English professors than work in ad agencies, and publishing papers is the way you compete for such jobs. Math would happen without math departments, but it is the existence of English majors, and therefore jobs teaching them, that calls into being all those thousands of dreary papers about gender and identity in the novels of Conrad. No one does that kind of thing for fun.
Of course Graham is committing the fallacy of generalizing from his own experiences. Graham is a programmer; I suspect that (1) he knows more math professors than English professors, and (2) he has an easier time seeing himself as a mathematician than as a literary critic. It’s interesting to juxtapose this with Graham’s comments in The Age of the Essay, in which he gives his spin on why people write essays and how real essays differ from those that one writes in school. Graham states that literary criticism was born when, in the late nineteenth century, American colleges started to transform themselves into research universities, and as a result the teachers of composition and rhetoric and so on needed something to research. He cites an article entitled “Where Do College English Departments Come From?” (William Riley Parker, College English, 28 (Feb. 1967), 339-351; JSTOR) for this. Graham’s point here is that students in English classes in high school and early in college are forced to write essays about literature when they could write more interesting essays about other things closer to their own experience. I agree with this, although I don’t know enough about current teaching of English to know if he’s attacking a straw man or not. But he seems to have an axe to grind against academic studies of English.
In What you’ll wish you’d known Graham suggests to high school students the tactic of “staying upwind” — major in math, say, instead of economics, because you can go from math to economics but not vice versa. In undergraduation he suggests constructing the “dropout graph” — field X is harder than field Y if more people switch from X to Y than the reverse. I’d like to see this dropout graph — perhaps the registrar’s office has the data? I can’t tell where English is in that graph — he doesn’t explicitly mention it in either a list of “worthwhile” departments or of “subjects with least intellectual content” — and I’d be curious to know where he’d put it.
Finally, I’ve known grad students in English, some of whom are now professors of English. They seem to be pretty into what they do, and not just because they want academic jobs.
A puzzle
Here’s a puzzle.
8809 = 6
7662 = 2
9312 = 1
8193 = 3
8096 = 5
7756 = 1
6855 = 3
9881 = 5
2581 = ?
Answer to follow in a few days. (I’ve already written it.)
