As I observed last week, four points is not enough to win one’s group in the World Cup. With four points (a win, a loss, and a draw) you have roughly a 50% chance of advancing to the knockout stage, based on historical data.
We can also verify this by working out all the possible results of a group. There are six games in each group, so 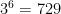
dplyr:
#flip(0) = 3, flip(1) = 1, flip(3) = 0
flip = function(x){(6-5*x+x^2)/2}
#column xy is the number of points that team x gets in the game between x and y
#a, b, c, d: total number of points for each team
#a_place: place of team A
#a_tie: number of teams with same number of points as A
#p_advance: probability that A advances
#p_place1: probability that A is in first place
groups = expand.grid(ab = c(0,1,3), ac = c(0,1,3),
ad = c(0,1,3), bc = c(0,1,3),
bd = c(0,1,3), cd = c(0,1,3)) %>%
mutate(a = ab + ac + ad,
b = flip(ab) + bc + bd,
c = flip(ac) + flip(bc) + cd,
d = flip(ad) + flip(bd) + flip(cd)) %>%
mutate(a_place = 4 - ((a >= b) + (a >= c) + (a >= d)),
a_tie = 1 + (a==b) + (a==c) + (a==d),
p_advance = ifelse(a_place >= 3, 0,
ifelse(a_place + a_tie <= 3, 1, (3-a_place)/(a_tie))),
p_place1 = ifelse(a_place >= 2, 0, ifelse(a_place + a_tie <= 2, 1, (2-a_place)/(a_tie)))
)
The data frame groups has 729 rows, one for each possible outcome of the six games in the group. See the example below, where A, B, C, and D have 4, 4, 3, and 5 points respectively. One way to get this is in the first row:
- A loses to B, A defeats C, A and D draw – 4 points for A
- (B defeats A), B loses to C, B and D draw – 4 points for B
- (C loses to A, C defeats B), C loses to D – 3 points for C
- (D and A draw, D and B draw, D defeats C) – 5 points for D
and the other is in the second, which is the same with A and B interchanged.
groups %>% filter(a==4, b==4, c==3, d==5)
ab ac ad bc bd cd a b c d a_place a_tie p_advance p_place1 p_place2
1 0 3 1 0 1 0 4 4 3 5 2 2 0.5 0 0.5
2 3 0 1 3 1 0 4 4 3 5 2 2 0.5 0 0.5In each of these cases team a is in a two-way tie (a_tie) for second place (a_place); if ties are broken at random, then team a has a probability 0.5 to advance, all coming from second place. Of course ties aren’t broken at random, but I’m not going to model goal differential.
Then we can compute the probability of advancing with each possible point total by aggregation:
groups %>% group_by(a) %>% summarize(prob = n()/3^6, prob_advance = mean(p_advance), prob_place1 = mean(p_place1))
# A tibble: 9 × 4
a prob prob_advance prob_place1
<dbl> <dbl> <dbl> <dbl>
1 0 0.0370 0 0
2 1 0.111 0 0
3 2 0.111 0.0123 0
4 3 0.148 0.0787 0.00231
5 4 0.222 0.543 0.0216
6 5 0.111 0.988 0.457
7 6 0.111 0.975 0.469
8 7 0.111 1 0.944
9 9 0.0370 1 1 To advance you need 7 points (to be sure); 5 will do except in freak cases. To win the group for sure you need 9 points, but 7 will do; 5 or 6 is a 50-50 shot. And we can plot it:

This reproduces what Greg Stoll found in 2014.
It’s natural to zoom in on the surprises:
- how to advance with two points. Here you want a group with scores 9-2-2-2 – one team wins against the other three (including you), those three trade draws, and you win the tiebreaker, meaning you lost your game to the 9-pointer by the fewest goals.
- how to win your group with three points. All six games must be draws, then you win the tiebreaker. (The first tiebreaker is goal difference, which would obviously be zero for all teams; the second is goals scored)
- how to fail to advance with five points. This requires a group with scores 5-5-5-0 – one team loses all three of its games, the other three trade draws, and you lose the tiebreaker, meaning you win your game with the 0-pointer by the fewest goals. This is the reverse of the 9-2-2-2 group above.
- how to fail to advance with six points. This requires a group with scores 6-6-6-0 – like the 5-5-5-0 group, except the three leading teams form a cycle of wins.
The first three have never happened in the World Cup; as I mentioned in my last post, the last one happened twice, both times in 1994.
If you want to know what probability a given team actually has of winning, see FiveThirtyEight. For the scenarios that cause it (including tiebreakers), see the NYT’s Upshot. The simplest scenario is that for the United States – if the US beats Iran today, they advance, otherwise they do not.