A quick way to see this: Trump won 306 electoral votes, Clinton 232. (There were faithless electors, but we can ignore them for the purposes of this question.). Trump won 30 states, Clinton 21. For the purposes of this post, DC is a state, which it probably also should be in reality.
Each state has as many electoral votes as it has senators and representatives combined. (DC gets 3.). Imagine breaking up the electoral votes in each state into two classes: the “senatorial” electoral votes (two per state), and the “representational” electoral votes (the other ones). Then Trump won the “senatorial” electoral votes by 60 to 42, leaving a 246-190 margin among the “representational” votes.
In 2000, on the other hand, Bush won 271 electoral votes in 30 states, and Gore 267 in 21 states; the “representational” votes were therefore split as 211 for Bush, 225 for Gore. If there were, say, twice as many Representatives (870 instead of 435 – and let’s keep the math simple and say DC gets 6 electoral votes in this scenario), and every state had twice as many electoral votes, then Bush would have had about (60 + 211 × 2) = 482 EV, and Gore (42 + 225 × 2) = 490 EV. Also in this world Nate Silver’s web site is named nineseventytwo.com (which is available, as of this writing). In fact, Bush would have won with any number of representatives less than 491; Gore with more than 655; and in between, the lead swings back and forth, according to a 2003 analysis by Michael G. Neubauer and Joel Zeitlin.
In short: 2000 was the way it was because small states are overrepresented in the Electoral College; 2016 was the way it was because the Electoral College is winner-take-all.
Quoc’s lab has a microcentrifuge, a piece of equipment that can separate components of a liquid by spinning around very rapidly. Liquid samples are pipetted into small tubes, which are then placed in one of the microcentrifuge’s 12 slots evenly spaced in a circle.
For the microcentrifuge to work properly, each tube must hold the same amount of liquid. Also, importantly, the center of mass of the samples must be at the very center of the circle — otherwise, the microcentrifuge will not be balanced and may break.
Quoc notices that there is no way to place exactly one tube in the microcentrifuge so that it will be balanced, but he can place two tubes (e.g., in slots 1 and 7).
Now Quoc needs to spin exactly seven samples. In which slots (numbered 1 through 12, as in the diagram above) should he place them so that the centrifuge will be balanced? Extra credit: Assuming the 12 slots are distinct, how many different balanced arrangements of seven samples are there?
To generate the subsets of [n] of size k, I just take:
the subsets that don’t contain n (which are therefore subsets of [n-1] of size k), and
the subsets that do contain n (which are therefore subsets of [n-1] of size k-1, with n adjoined) (I learned this a good two decades ago, from section 3.6 of Herb Wilf’s notes East Side, West Side.)
Then iterate over the subsets to find their centers of mass:
our_comb = combinations(12, 7)
com_x = rep(NA, length(our_comb))
com_y = rep(NA, length(our_comb))
for (i in 1:length(our_comb)){
com_x[i] = mean(x[our_comb[[i]]])
com_y[i] = mean(y[our_comb[[i]]])
}
So our_comb runs through the combinations, and com_x and com_y are the x- and y-coordinates of the center of mass. Plotting the centers of mass gives we get an attractive symmetric pattern. Here I’ve plotted transparent points, so the darker points are points that arise from more distinct combinations. The outermost points represent the most imbalanced centrifuges – for example the one closest to the top represents loading slots 9, 10, 11, 12, 1, 2, and 3. The main question is: how many points are on top of each other at the very center.
Centers of mass of all subsets of 7 of the 12 centrifuge positions.
I can extract those subsets from the matrix our_comb and build them into a matrix for looking at. There’s a small problem in that we used floating-point arithmetic, so the coordinates don’t come out exactly at zero, but it’s enough to ake the ones that are “close enough”:
(The order here is lexicographic order, but you have to read the rows backwards.)
If you can make sense of this pile of numbers without making some pictures, good for you! But I am human, though a mathematician, so let’s plot. Here big black dots represent the loaded spots, and small blue dots represent the non-loaded spots.
(And yes, it’s in base R graphics. It’s been a while since I’ve used those – at my day job it’s all ggplot all the time.)
par(mfrow = c(4, 3), mar = c(1, 1, 1, 1))
for (i in 1:nrow(balanced_combs)){
full = balanced_combs[i,]
empty = setdiff(1:n, balanced_combs[i,])
plot(x[full], y[full], pch = 19,cex = 2,
asp = 1, axes = FALSE, xlab = '', ylab = '',
xlim = c(-1.25, 1.25), ylim = c(-1.25, 1.25))
points(x[empty], y[empty], pch = 19, cex = 1, col = 'lightblue')
}
So there are 12 ways to load the centrifuge… but we can clearly see that all of them are really just rotations of a single pattern. To me the visually most convenient representative of that pattern is the third one in the third row, which has loadings at 12, 1, 4, 5, 7, 8, and 11.
We can play a little game of connect-the-dots to see why this pattern is balanced. Connect 12, 4, and 8 to form an equilateral triangle. Connect 1 and 7; connect 5 and 11. Like this:
12-hole centrifuge loaded with 7; symmetric subsets specified
Each of those three subsets has its center of mass at the center of the circle, so the whole arrangement does too.
That decomposition turns out to be the key to the general problem of which centrifuge sizes can be loaded with which number of tubes and remain balanced. Stay tuned.
Me: I can’t do that, because rainbow color maps are considered harmful. This is especially true because if we’re going to use one, shouldn’t it be green for “go” and red for “stop”.
Partner: just shut up and color.
(The original version of this meme didn’t have the colors, so you can make whatever palette you want, as in this example.)
Evelyn Lamb has a delightful page-a-day calendar. Today (yes, a few days late) I learned that TWENTY NINE is the only word in English that is written with a number of straight-line strokes equal to its value. (This is in a sans serif font; in particular I is one stroke, not three.)
English is surprisingly rich in numbers that have all straight-line strokes. In the Latin alphabet the letters that are all straight lines are A, E, F, H, I, K, L, M, N, T, V, W, X, Y, Z. That leads to the following words that are all straight-lined and appear in numbers, and the number of straight lines that make them up:
– having more strokes than their value: FIVE (10), NINE (11), ELEVEN (19), TWELVE (18), FIFTEEN (20), NINETEEN (23)
– having less strokes than their value: TEN (9), TWENTY (18), FIFTY (12), NINETY (16)
Any word that equals its own value must combine elements from both these lists, and it’s not hard to see that TWENTY NINE is the only one that works. The full list of straight-line numbers in English is: 5, 9, 10, 11, 12, 15, 19, 25, 29, 55, 59, 95, 99. (All the larger numbers include “HUNDRED” or “THOUSAND” or something ending in “-ION”, so we can stop there.)
Evelyn suggests this as part of how to memorize the largest known prime (it’s a Mersenne prime, and she suggests doing it in binary so every bit is 1, so the hard part is remembering where you are).
It’s hard to even find straight-line numbers in other languages, because a lot of the alphabet is missing. They include:
German ZWEI (2), ZEHN (10), ELF (11)
Dutch EEN (1), TWEE (2), ZEVEN (7), TIEN (10), ELF (11) (edited 9/3: also ZWAALF (12))
Norwegian has a lot: EN (1), FEM (5), ATTE (8), NI (9), TI (10), ELLEVE (11), FEMTEN (15), ATTEN (18), NITTEN (19), FEMTI (50), ATTI (80), NITTI (90) (and also 55 = FEMTIFEM, 58, 59, 85, 88, 89, 95, 98, 99)
As does Danish: EN, FEM, NI, TI, ELLEVE, FEMTEN, ATTEN, NITTEN, with the same meanings as in Norwegian, but then the bigger numbers are formed irregularly.
Swedish has less: EN (1), FEM (5), ATTA (8), ELVA (11) – the numbers are very similar to Norwegian but the “-teen” ending is “-ton”, not “-ti” like Norwegian.
Spanish VEINTE (20), MIL (1000), and MIL VEINTE (1020)
Italian VENTI (20), MILLE (1000), and MILLEVENTI (1020)
Portuguese VINTE (20), MIL (1000) and MIL E VINTE (1020)
French MILLE (1000), but not VINGT (20)
ELVA (Swedish for 11) is the only other one I could find that also has the self-referential property, and the Chinese numerals 一, 二, 三 if you want to stray from the alphabetic world. (Edited 9/3: also Dutch TIEN = 10, which I inexplicably missed before.)
(This post was edited to add the list of numbers and to clarify that ELVA is not the only straight-line number outside of English, but the only one I could find with this self-referential property.)

 . This is nonstandard, but the result looks like a clock, so it’s easier to visualize:
. This is nonstandard, but the result looks like a clock, so it’s easier to visualize:
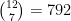 ways that we could pick 7 out of the 12 holes. To generate a list of these I can use the following R function:
ways that we could pick 7 out of the 12 holes. To generate a list of these I can use the following R function:


