People are interested in the odds for the “Super Bowl Squares” game: see for example the Harvard Sports Analysis Collective in 2013 and Mike Beuoy writing for FiveThirtyEight in 2014. The way the game works is as follows:
- players pay money into a pool.
- a 10 by 10 grid is made, and the rows and columns are marked 0 through 9.
- One team’s name is written corresponding to the rows, and the other to the columns
- the squares of the grid are assigned randomly to the players, proportionally to the amount of money they paid.
- after each quarter of the Super Bowl, look at the last digit of the number of points each team has scored. This gives a row and a column, and the person who has the corresponding square gets some money (say, one-tenth of the pool)
- at the end of the game, do the same. The person who has the corresponding square gets a lot of money
This game suffers from a flaw – there are lots of squares that are pretty much worthless, so after the random assignment happens, if you have those squares you won’t win. I couldn’t get quarter-by-quarter data, but below see the number of times that each game score occurred, where the scores are reduced mod 10 (i. e. we look at just the last digit). Data is from pro-football-reference.com. Obviously using (winner, loser) isn’t exactly the same as using (home team, away team) or some other assignment of teams done before the game, but I don’t think the conclusions here are very sensitive to that.
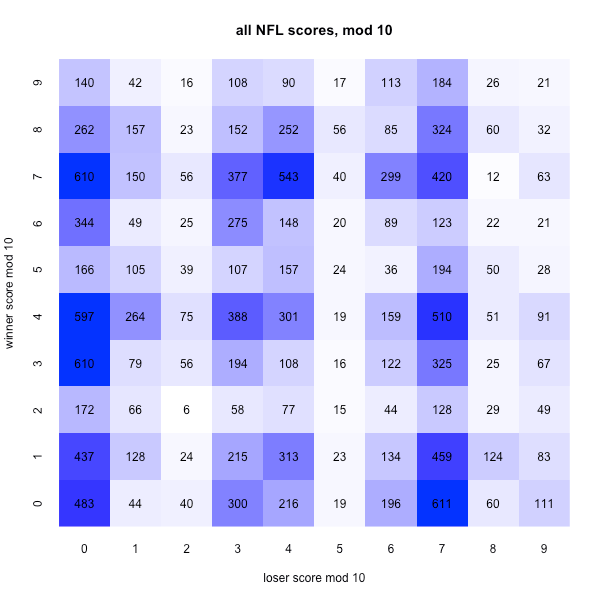
The most common squares are (0, 7) (Note: I’ll refer to squares by (winner score, loser score), which doesn’t agree with the picture but does agree with the way scores are usually read), which occurs 611 times (including the most common single score, 20-17, which has occurred 248 times), and (7, 0) which occurs 610 times (led by 133 occurrences of 17-10 and 102 occurrences of 27-20). On the flip side, (2, 2) has only occurred six times (two games each of 12-12 and 42-32, and one each of 22-12 and 42-22). If you know anything about football, you know that scores come in sevens and threes, for the most part, and this has the property of making certain last digits a lot more common than others.
But there’s an easy fix. What if we play mod 9? Then the distribution of historical scores looks like this:
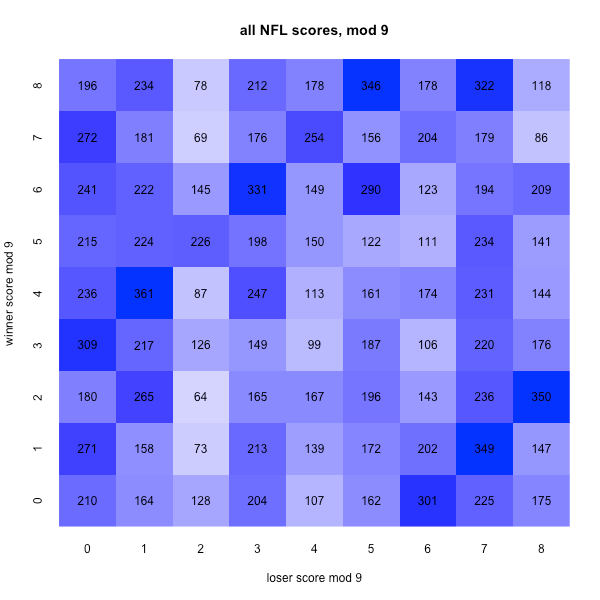
There’s still some unevenness, no doubt about it. But there aren’t terrifying white gaps signifying scores that never happen. The most common square is now (4, 1), which occurs 361 times, most commonly as 13-10, 31-28, or 31-10. But even the lowly (2, 2) occurs 64 times in the historical record, most frequently as 38-20, 20-20, or 29-20. (In fact, all but two of the (2, 2) games had at least one team scoring exactly 20.)
And you don’t even have to do division to reduce a number mod 9 – just add the digits of the score up and repeat until you get a single-digit number. 9 counts as 0.
What about if you don’t have a lot of friends and want to do a smaller pool? Mod 6 works well, and has the advantage that you can assign the squares by rolling a die:

The most common square is (0, 3) (most frequently represented by 24-21 or 30-27) and the least common is (4, 5) (most frequently represented by 28-17 or 34-17, which at least sound like plausible football scores).
But whatever you do, don’t play mod 7:

This is basically a fancy way of beting on how many field goals each team will score: “0” means no field goals, “3” means one field goal, and so on. Also it defeats the purpose of gambling, which is to make the game more interesting – a touchdown plus extra point doesn’t change anything.
Go… um… seriously, I can’t remember who’s playing. All I know is that the people I know back in San Francisco are complaining and perhaps vandalizing statues.
