From Josh Wills at Cloudera, a post on reservoir sampling.
Evelyn Lamb has compiled a list of mathy ladies to follow on Twitter.
Stephen Wolfram (and presumably part of his army of people working for him) have some interesting visualizations of Data Science of the Facebook world.
Brian Hayes maps the Hilbert curve.
Dana Mackenzie at Slate writes on the mathematics of jury sizes. Also at Slate, Phil Plait writes for the Bad Astronomy blog on the analemma.
How to sort comments intelligently and this post on Bayesian methods for multi-armed bandits are part of Cam Davidson-Pilon’s book Probabilistic Programming and Bayesian Methods for Hackers. I found Davidson-Pilon via his list of machine learning counterexamples.
Kenneth Appel (of four colors suffice fame) died.
 square inches, which is about 63.62. An eight-inch square, of course, has area 64 square inches. Not bad!
square inches, which is about 63.62. An eight-inch square, of course, has area 64 square inches. Not bad! exactly; solving for
exactly; solving for  gives $\pi = 256/81″, which is often credited as an Egyptian approximation to
gives $\pi = 256/81″, which is often credited as an Egyptian approximation to 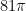 is about 254.46 – but it has the added “virtue” that 256 is a power of two, and 81 is a power of three. We could write
is about 254.46 – but it has the added “virtue” that 256 is a power of two, and 81 is a power of three. We could write 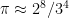 – it looks nicer that way, I think.
– it looks nicer that way, I think.
