The Major League Baseball postseason is starting just as I write this.
From the National League, we have Washington, St. Louis, Pittsburgh, Los Angeles, and San Francisco.
From the American League, we have Baltimore, Kansas City, Detroit, Los Angeles (Anaheim), and Oakland.
These match up pretty well geographically, and this hasn’t gone unnoticed: see for example the New York Times blog post “the 2014 MLB playoffs have a neighborly feel” (apologies for not providing a link; I’m out of NYT views for the month, and I saw this back when I wasn’t); a couple mathematically inclined Facebook friends of mine have mentioned it as well.
In particular there are three pairs of “same-market” teams in here: Washington/Baltimore, Los Angeles/Los Angeles, San Francisco/Oakland. How likely is that?
(People have pointed out St. Louis/Kansas City as being both in Missouri, but that’s a bit more of a judgment call, and St. Louis is only marginally closer to Kansas City than it is to Chicago. I realize that Washington/Baltimore is also a judgment call, but ever since the Nationals set up shop in Washington the Baltimore Orioles’ owner has claimed that he’s financially harmed by the existence of the Nationals.)
Now, there are a total of five same-market pairs of teams (the others being the two New York teams and the two Chicago teams). There are two pairs (New York and Washington/Baltimore) involving teams in the Eastern division of their respective leagues; one pair (Chicago) involving teams in the Central division; and two pairs (SF/Oakland and Los Angeles) involving teams in the Western division. The way the baseball playoffs work currently is this:
- there are thirty teams, divided into two leagues; each has three divisions (East, Central, West) of five teams each.
- in each division, the team with the best record makes it to the playoffs.
- in each league, the two teams among the non-winners with the best record also make it to the playoffs.
(I know, there’s some debate about whether the wild card game is “really” a playoff game. Let’s ignore that.)
This is starting to sound just asymmetric enough that I’d only figure out the answer manually if I were assigning it to a class. I don’t teach any more. Let’s simulate!
Here’s some R code. The way this works is as follows:
– the function pick.teams.from.league returns five integers in the range 1, 2, …, 15, intended to correspond to the teams that make the playoffs from one league. The East division is represented by the numbers 1 through 5; the Central, 6 through 10; the West, 11 through 15.
– we encode teams that share a market as 1, 2, 6, 11, 12, which are chosen so there’s the right number of them in each division.
– the function pick.playoffs returns the number of pairs of same-market teams who make it to the playoffs in a simulated season. These are just numbers in the set {1, 2, 6, 11, 12} that appear in both the NL and AL lists for a given season.
same.market.teams = c(1, 2, 6, 11, 12)
pick.teams.from.league = function(){
east.winner = sample(1:5, 1)
central.winner = sample(6:10, 1)
west.winner = sample(11:15, 1)
nonwinners = setdiff(1:15, c(east.winner, central.winner, west.winner))
wild.cards = sample(nonwinners, 2)
return(c(east.winner, central.winner, west.winner, wild.cards))
}
pick.playoffs = function(same.market.teams){
nl.teams = pick.teams.from.league()
al.teams = pick.teams.from.league()
matches = intersect(intersect(nl.teams, al.teams), same.market.teams)
return(length(matches))
}
Then we simulate a million seasons:
table(replicate(10^6, pick.playoffs(same.market.teams)))
Output:
| 0 | 1 | 2 | 3 | 4 | 5 |
| 534618 | 380675 | 79075 | 5521 | 111 | 0 |
So in a million simulated seasons: 5521 of them (0.55%) had three same-market pairs make the playoffs (like this year), and 111 of them (0.01%) had four. Never did all five pairs of same-market teams make the playoffs.
Of course this ignores the fact that perhaps not all teams are equally likely to make the playoffs. Maybe large-market teams are more likely to make it, because baseball is generally a regional sport (people don’t follow the league so much as they follow their team). Maybe sharing a market hurts teams. Maybe it helps – you do better because you have competition for the entertainment dollar. Who knows?
But in short, yes, this year is unusual.
 is proportional to
is proportional to  . (But note that
. (But note that  . Let
. Let  (i. e. measure money in units of billions of dollars) and you get that
(i. e. measure money in units of billions of dollars) and you get that  , if “typical” means median.
, if “typical” means median. , so you get
, so you get  , or $\alpha = 31/21 \approx 1.48$, if “typical” means mean.
, or $\alpha = 31/21 \approx 1.48$, if “typical” means mean.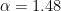 (derived from assuming the mean billionaire has a net worth of 3.1 billion), 81 percent of billionaires have less net worth than what the article calls the “typical” billionaire, and the median billionaire has a net worth of “only” 1.6 billion. In contrast, a Pareto distribution with
(derived from assuming the mean billionaire has a net worth of 3.1 billion), 81 percent of billionaires have less net worth than what the article calls the “typical” billionaire, and the median billionaire has a net worth of “only” 1.6 billion. In contrast, a Pareto distribution with  , such as any one where the median is at least twice the minimum, doesn’t even have a well-defined mean. (Of course the actual distribution of billionaire net worths has a well-defined mean, whatever it is, because there are a finite number of them.)
, such as any one where the median is at least twice the minimum, doesn’t even have a well-defined mean. (Of course the actual distribution of billionaire net worths has a well-defined mean, whatever it is, because there are a finite number of them.)
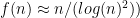 , so let’s divide by that to get a plot of the “normalized” number of solutions:
, so let’s divide by that to get a plot of the “normalized” number of solutions: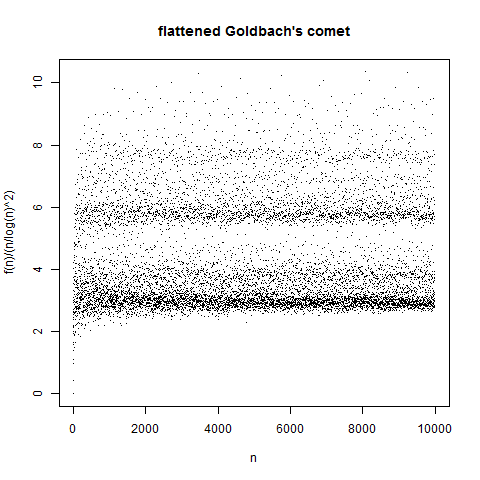
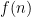 , the function which is
, the function which is 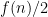 when
when  is divisible by 3 and
is divisible by 3 and  . But there’s still some banding:
. But there’s still some banding:

 we get that there are
we get that there are 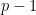 ways to pair up residue classes
ways to pair up residue classes 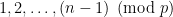 to get the residue class 0 (i. e. multiples of
to get the residue class 0 (i. e. multiples of  ways to get each of the classes
ways to get each of the classes  . That is, multiples of
. That is, multiples of 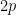 are more likely than nonmultiples to be sums of randomly chosen primes, by a factor of
are more likely than nonmultiples to be sums of randomly chosen primes, by a factor of  . Correcting for this, let’s plot
. Correcting for this, let’s plot