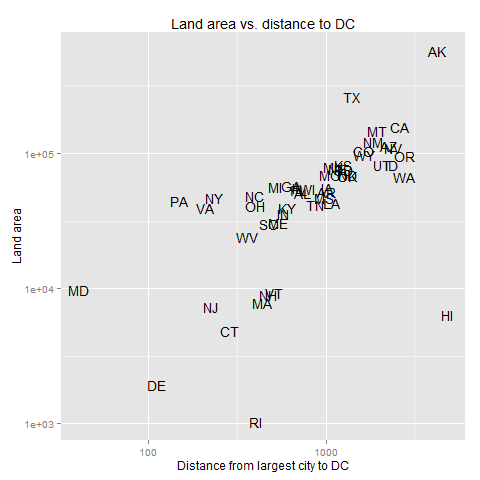
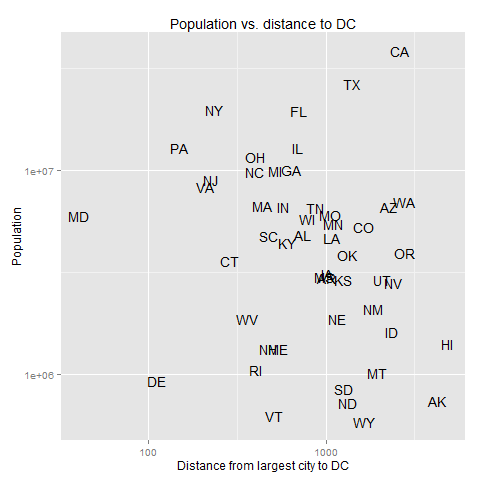
Matt O’Brien at the Washington Post’s Wonkblog has an infographic that contains the following information:
| quintile of income distribution | first | second | third | fourth | fifth |
| % of college graduates from poor families | 16 | 17 | 26 | 21 | 20 |
| % of high school dropouts from rich families | 16 | 35 | 30 | 5 | 14 |
This comes from a paper entitled Equality of opportunity: definitions, trends, and interventions by Richard V. Reeves and Isabel V. Sawhill. The second row is from their figure 10, the first from their figure 11. Rich and poor families are those in the top and bottom income quintiles; the table is looking at their children’s income at age 40.
The interpretation that O’Brien suggests is that “Even poor kids who do everything right don’t do much better than rich kids who do everything wrong. Advantages and disadvantages, in other words, tend to perpetuate themselves. ”
And that is true, but there’s something interesting I can’t help but see here – the distribution of incomes for high school dropouts from rich families appears to have two peaks. Are there some of these “rich” who have gotten a leg up from their families while others didn’t? More likely, though, is that the sample size involved is just too small to make detailed claims like this. (And the 80th percentile is hardly rich.). I bet it’s possible to pull off something like that in a society with multiple castes that hardly overlap, but that’s not the situation in the US – we have a lot of income inequality but there are smooth gradations between the different segments of the income distribution.
 . And for concreteness, let’s say you want to bet on the Giants against the Royals. (I used to live in San Francisco and have never been anywhere near Kansas City.) The goal is to put together a series of bets that will leave you with
. And for concreteness, let’s say you want to bet on the Giants against the Royals. (I used to live in San Francisco and have never been anywhere near Kansas City.) The goal is to put together a series of bets that will leave you with  if the Giants win and
if the Giants win and  if they lose.
if they lose. , before game
, before game  :
: ;
; ;
;
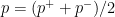 .
. or
or  ; that is, the change in your bankroll is twice the change in probability. This is also true if the Giants lose. At the beginning your bankroll is
; that is, the change in your bankroll is twice the change in probability. This is also true if the Giants lose. At the beginning your bankroll is  , so your bankroll is always twice the win probability. In the end it’s 2 if the Giants win and 0 if they lose, simulating the desired bet.
, so your bankroll is always twice the win probability. In the end it’s 2 if the Giants win and 0 if they lose, simulating the desired bet.