James Tanton asked in a tweet: what’s the probability that an n-digit palindrome chosen at random is divisible by 11?
This depends heavily on $n$. In particular, if $n$ is even, the probability is 1. We can notice that $11, 1001, 100001, \cdots$ are each multiples of 11 (these are $11 \times 1, 11 \times 91, 11 \times 9091, \cdots$) and write a palindrome as a sum of multiples of these. For example
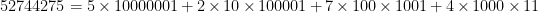
is a multiple of 11.
Let’s also consider the case where the digit count is odd. This is a bit trickier, and Mike Lawler (https://mikesmathpage.wordpress.com/2015/01/20/a-nice-divisibility-rule-problem-from-james-tanton/) and his younger son worked out that out of the 900 palindromes with five digits, 82 are divisible by 11.. In the three-digit case it’s not hard to find the full list of palindromes divisible by 11, and there are eight of them, from a total of 90. they’re 121, 242, 363, 484, 616, 737, 858, 969. There’s an obvious pattern here – consecutive elements of the list differ by 121, except when they don’t (going from 484 to 616).
So let’s go back to the notation and say we’re consider an  -digit palindrome where
-digit palindrome where 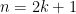 . We want to iterate over possible “first halves” of the palindrome and figure out what the middle digit should be: we’re answering questions like “what five-digit palindrome starting with 28 is divisible by 11?” There is at most one
. We want to iterate over possible “first halves” of the palindrome and figure out what the middle digit should be: we’re answering questions like “what five-digit palindrome starting with 28 is divisible by 11?” There is at most one  -digit palindrome with any first
-digit palindrome with any first  -digit number which is divisible by 11. Consider the numbers
-digit number which is divisible by 11. Consider the numbers
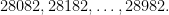
Each of these differs by 100 from the last one, which is one more than a multiple of 11, so when we reduce mod 11 we get
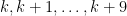
which are all different. Unless 28082 happens to be one more than a multiple of 11, one of these is a multiple of 11. As it turns out, 28082 is one {\it less} than a multiple of 11, and 28182 is a multiple of 11:  .
.
So there is either zero or one palindrome of each of the forms  . When is there no such palindrome? Observe that, for example,
. When is there no such palindrome? Observe that, for example,
 $
$
and so 12000 and 21 differ by a multiple of 11. So 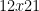 and
and 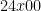 are congruent mod 11. To get to be a multiple of 11 we need
are congruent mod 11. To get to be a multiple of 11 we need  (that is,
(that is,  ) to be a multiple of 11 – so we take
) to be a multiple of 11 – so we take 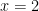 . Indeed,
. Indeed,  is a multiple of 11, with
is a multiple of 11, with 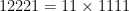 .
.
But consider, for example, the number 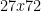 . This is congruent to
. This is congruent to  mod 11, and is a multiple of 11 if and only if
mod 11, and is a multiple of 11 if and only if 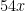 is – but none of
is – but none of  are divisible by 11. Working backwards, this can be traced back to the fact that
are divisible by 11. Working backwards, this can be traced back to the fact that  .
.
So the five-digit palindromes divisible by 11 are in one-to-one correspondence with the integers in $10, 11, \ldots, 99$ which are not congruent to 5 mod 11 — of which there are  . This generalizes to
. This generalizes to 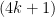 -digit palindromes: there are 8182 nine-digit palindromes divisible by 11 (out of 90000 nine-digit palindromes), 818182 thirteen-digit palindromes (out of , and so on. These look an awful lot like the decimal expansion of
-digit palindromes: there are 8182 nine-digit palindromes divisible by 11 (out of 90000 nine-digit palindromes), 818182 thirteen-digit palindromes (out of , and so on. These look an awful lot like the decimal expansion of 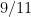 , and in fact
, and in fact
For palindromes with three, seven, eleven, … digits the arithmetic works out a bit differently – but the final result can be expressed in this form: the number of -digit palindromes divisible by 11 is the closest integer to  . The probability that Tanton asked for is almost exactly 1/11 — the same as the probability that a random integer is divisible by
. The probability that Tanton asked for is almost exactly 1/11 — the same as the probability that a random integer is divisible by  . The fact that the palindrome constraint has no effect is… obvious? Totally surprising. To be honest I don’t know.
. The fact that the palindrome constraint has no effect is… obvious? Totally surprising. To be honest I don’t know.
