Here’s another brute-force number theory puzzle, in the spirit of the Russian puzzle I looked at a couple weeks ago. From what would Martin Gardner tweet: “Two triangles share one angle but have six different side lengths (all whole numbers between 1 and 9). Find those lengths.”
Do we expect such triangles to exist? Well, clearly there are lots of different-sized right triangles, which share an angle. To take the smallest possible example, 3-4-5 and 6-8-10 are both the sides of right triangles, and they share an angle. But sadly, 10 is too large…
This is a bit tricky to think about, because the angles of an integer-sided triangle aren’t going to be anything nice. So instead of looking at the angles themselves let’s look at their cosines. Given a triangle with sides having lengths (a, b, c), the angle C, opposite the side of length c satisfies
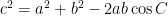
which we can rearrange to give

This is just the law of cosines from “high school trigonometry”, which is a generalization of the Pythagorean theorem to non-right-angled triangles.
So now the search for a solution is just bookkeeping. Let’s look at all the possible triplets (a, b, c) of distinct integers that could be the sides of a triangle. For the sake of keeping things canonical, let’s force  . The triangle inequality says that
. The triangle inequality says that  , or
, or  , so we get
, so we get  . Furthermore we can see that a must be at least 4, since each of those four inequalities is strict. So we loop over all those possible triples and store them in a Python dictionary according to the cosines of their angles. The following code will ask for an upper bound on the side lengths and carry out the search.
. Furthermore we can see that a must be at least 4, since each of those four inequalities is strict. So we loop over all those possible triples and store them in a Python dictionary according to the cosines of their angles. The following code will ask for an upper bound on the side lengths and carry out the search.
#Import some useful data structures.
from collections import defaultdict
from sets import Set
#Greatest common divisor (by the Euclidean algorithm). For reducing fractions.
def gcd(a,b):
while b:
a, b = b, a%b
return a
#Takes as input the three sides of a triangle;
#Outputs red_num, red_den such that red_num/red_den is the cosine of the angle opposite the first side given
#as a fraction in lowest terms
def cosine_law(c, a, b):
raw_num = (-c**2 + a**2 + b**2)
raw_den = (2*a*b)
g = gcd(raw_num, raw_den)
red_num = raw_num/g
red_den = raw_den/g
return red_num, red_den
out = defaultdict(set)
maxn = int(raw_input("Largest side to allow? ")) + 1
#Loop over possible triples a, b, c with a > b > c > a-b
#(i. e. in decreasing order and satisfying the triangle inequality)
#and add the cosines of their angles to the dictionary out
for a in range(4, maxn):
for b in range(-int(-a/2), a):
for c in range(a-b+1, b):
if gcd(gcd(a,b),c) == 1:
cosA = cosine_law(a,b,c)
cosB = cosine_law(b,a,c)
cosC = cosine_law(c,a,b)
#store with vertex first, then larger of two second
out[cosA].add((a,b,c))
out[cosB].add((b,a,c))
out[cosC].add((c,a,b))
#Look through out for pairs of triangles which share an angle
#and have all three sides different.
numsols = 0
for key in out:
if len(out[key]) >= 2:
triangles = list(out[key])
for i in triangles:
for j in triangles:
sides = Set([i[0], i[1], i[2], j[0], j[1], j[2]])
if len(sides) == 6 and i[0] >= j[0]:
#print key, i, j
numsols = numsols+1
And if we input 9 when it asks for that largest side the output is precisely
(11, 16) (6, 8, 7) (3, 4, 2)
The 2-tuple is the rational number 11/16, the cosine of the angle that these triangles have in common. The triplets represent triangles with an angle  , with the side opposite that angle listed first. So the angle opposite the side of length 6 in a 6-7-8 triangle and the angle opposite the side of length 3 in a 2-3-4 triangle both have cosine $11/16$; they are both angles of $\cos^{-1} 11/16$, or about 46.6 degrees.
, with the side opposite that angle listed first. So the angle opposite the side of length 6 in a 6-7-8 triangle and the angle opposite the side of length 3 in a 2-3-4 triangle both have cosine $11/16$; they are both angles of $\cos^{-1} 11/16$, or about 46.6 degrees.
This leads naturally to the question: are such pairs of triangles rare? The answer is “not at all”. There are 30 solutions to this problem with all sides under 15, 951 with all sides under 30, and 81,014 with all sides under 100.
In fact, heuristically, we expect lots of such solutions. The number of different integer triangles with all their sides less than n is on the order of n3. From the law of cosines, the angles of these triangle will have cosines that are rational numbers with numerator and denominator on the order of n2; there are n4 such different numbers. We can wave our hands and say the magic words birthday problem; since the number of possible cosines is much greater than the square root of the number of angles we need to find cosines for, if everything happens “at random” there ought to be lots of collisions — and indeed there are.
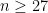 ? Among the first n – 1 plate appearances there must be exactly 26 outs; the probability of this happening is
? Among the first n – 1 plate appearances there must be exactly 26 outs; the probability of this happening is  . Then the last plate appearance must be an out, which happens with probability p. So the probability of this game ending in
. Then the last plate appearance must be an out, which happens with probability p. So the probability of this game ending in  plate appearances is
plate appearances is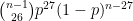 .
. we get this model’s estimated probability of a perfect game. It’s (0.706)27, which is about one per 12,000 team-games. There have been
we get this model’s estimated probability of a perfect game. It’s (0.706)27, which is about one per 12,000 team-games. There have been 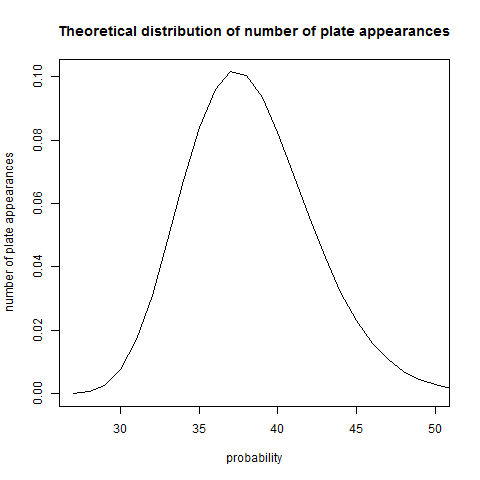

 , where
, where  . This is about
. This is about  , or one in thirty trillion. (The probably that five or more balls will be hit to me is orders of magnitude lower than that.)
, or one in thirty trillion. (The probably that five or more balls will be hit to me is orders of magnitude lower than that.) , which is about one in two million. So this should have happened 35 to 40 times last year – it’s just that most of the people who it happened to didn’t bother telling anybody! (Other than their friends, who probably didn’t believe them.)
, which is about one in two million. So this should have happened 35 to 40 times last year – it’s just that most of the people who it happened to didn’t bother telling anybody! (Other than their friends, who probably didn’t believe them.) distinct riffle shuffles of n cards. For example, consider a five-card deck, which is initially in the order 1, 2, 3, 4, 5. Then a riffle shuffle consists of:
distinct riffle shuffles of n cards. For example, consider a five-card deck, which is initially in the order 1, 2, 3, 4, 5. Then a riffle shuffle consists of: possible ways to make a permutation from this – we decide which two slots to put the 4 and the 5 in, and then everything else is forced. For example if we decide that 4 and 5 will go in the second and fourth positions, we must get 14253. In general if we have k cards in the left-hand pile and
possible ways to make a permutation from this – we decide which two slots to put the 4 and the 5 in, and then everything else is forced. For example if we decide that 4 and 5 will go in the second and fourth positions, we must get 14253. In general if we have k cards in the left-hand pile and 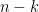 cards in the right-hand pile, we have $\latex n \choose k$ possible shuffles. Furthermore we can decompose any one of these permutations into two “rising sequences” in exactly one way, so it can come from exactly one cut — with a single exception. That exception is the identity permutation
cards in the right-hand pile, we have $\latex n \choose k$ possible shuffles. Furthermore we can decompose any one of these permutations into two “rising sequences” in exactly one way, so it can come from exactly one cut — with a single exception. That exception is the identity permutation  , which we can obtain from any of the n+1 possible cuts — so we must subtract n for the duplications. (If you put probabilities on this it becomes the
, which we can obtain from any of the n+1 possible cuts — so we must subtract n for the duplications. (If you put probabilities on this it becomes the 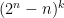 possible results. There will actually be less, because there are relations among the permutation subgroup generated by the riffle shuffles. (In less fancy language, there are sequences of different shuffles which give the same result. It’s the
possible results. There will actually be less, because there are relations among the permutation subgroup generated by the riffle shuffles. (In less fancy language, there are sequences of different shuffles which give the same result. It’s the 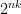 to make the math easier. Now, there are
to make the math easier. Now, there are 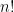 permutations; this is greater than
permutations; this is greater than  by a standard bound. So just in order to have
by a standard bound. So just in order to have  , or, taking nth roots of both sides,
, or, taking nth roots of both sides, 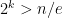 . Taking base-2 logs, we get
. Taking base-2 logs, we get  .
.