Isaias will be the ninth tropical storm of the season, likely to form on July 30. This is unusually early. From CNN on July 28: “Once it is given the name Isaias — pronounced (ees-ah-EE-as) — it will be the earliest storm to begin with an “I” on record. The previous record was set on August 7, 2005, part of the busiest season to date.” Storms are named in alphabetical order, so a storm starting with “I” is the ninth storm of the season.
This did seem early to me. The recent example that I remember Irma, which made landfall on the mainland US on September 10, 2017. (I spent a day seeing lots of people with Florida license plates driving around Atlanta, thinking “at least I don’t live in Florida!”, and then the next day having my power out and being glad that the trees the storm took out in my backyard were ones that needed taking out anyway.)
What does this mean for the rest of the hurricane season? Should we expect a busy one?
There’s an R package, HURDAT, that compiles the NOAA hurricane database. For each year, we can count the number of storms. First let’s make a list of all the storms:
library(HURDAT)
library(lubridate)
al <- get_hurdat(basin = 'AL') cutoff_month = 7 cutoff_day = 29 storms = al %>% group_by(Key) %>% filter(Status %in% c('TS', 'HU')) %>%
mutate(rk = rank(DateTime)) %>% filter(rk == 1) %>%
mutate(season_part = ifelse(month(DateTime) < cutoff_month |
month(DateTime) == cutoff_month & day(DateTime) <= cutoff_day, 'early', 'late')) %>%
select(Key, Name, DateTime)
and count the storms by time in the season:
storm_counts = storms %>% mutate(yr = year(DateTime)) %>%
group_by(yr, season_part) %>% count()
But how do we know about are storms? Not all storms were observed in the past, because some stay out to sea. The “satellite era” began in 1966, according to this article about this year’s Tropical Storm Gonzalo (the earliest “G” storm ever). So let’s plot the number of storms before and after July 29, separately for each of the two “eras”.
satellite_start = 1966
storm_counts %>% spread(season_part, n, 0) %>%
mutate(satellite = ifelse(yr >= satellite_start, 'satellite', 'pre-satellite')) %>%
ggplot() + facet_wrap(~satellite) + geom_jitter(aes(x=early, y=late)) +
stat_smooth(aes(x=early, y=late, group = satellite), method = 'lm') +
scale_x_continuous(paste0('storms before ', cutoff_month, '/', cutoff_day)) +
scale_y_continuous(paste0('storms after ', cutoff_month, '/', cutoff_day))
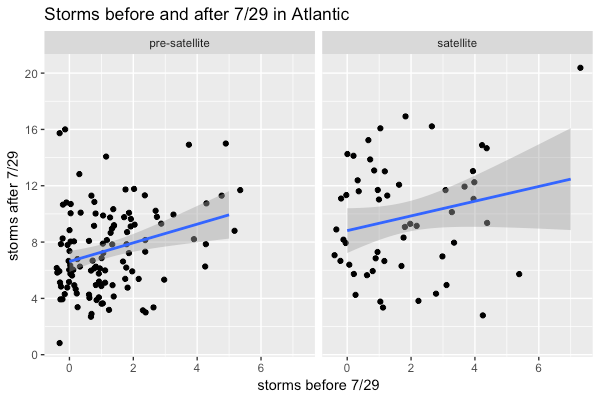
But 2005 is a big outlier! I remember that season. Of course it was the year of Katrina. And in December there was a hurricane named Epsilon, which I could not take seriously because epsilon is small. Indeed if we drop it the effect of early-season storms on late-season ones gets much smaller.
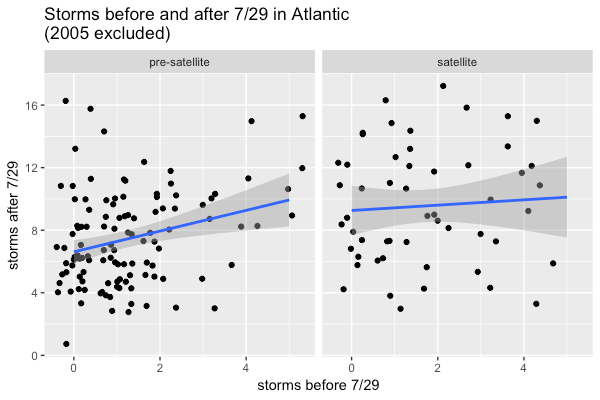
So there’s a small effect – but not as large as might be expected! So how many storms will we have this season? Calling predict(storm_model, data.frame(early = 9), interval = 'prediction', level = 0.95), gets a 95% prediction interval for the number of storms in the rest of the season: 12.5 plus or minus 7.2. So we could reasonably have as few as 5 more or as many as 20 more, for a total of 14 to 29.
A 50% prediction interval goes from 10 to 15 more storms in the remaining part of the season, for a total of 19 to 24. For comparison, the quartiles of the distribution of the number of storms after 7/29 in the satellite era are 7 and 12. So if we knew nothing about what’s happened so far, we’d give a 50% prediction interval of 16 to 21 storms for the number at the end of the season.
Let’s see what happens. And let’s hope these storms stay far out to sea, because pandemics and hurricanes don’t seem very compatible.
 .
. with
with  then there are two remaining sub-pools of k-2 and n-k-1 lanes.
then there are two remaining sub-pools of k-2 and n-k-1 lanes. ,
, $
$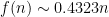 , which agrees with the Monte Carlo simulations in
, which agrees with the Monte Carlo simulations in  is
is  . Kranakis and Krizanc have some online notes on the
. Kranakis and Krizanc have some online notes on the 