The journal Basic and Applied Social Psychology is banning the NHSTP. (That’s the “null hypothesis statistical testing procedure” you might remember from an intro stats course.) This includes banning confidence intervals, thanks to the duality between confidence intervals and hypothesis tests. The journal’s editors write that:
We hope and anticipate that banning the NHSTP will have the effect of increasing the quality of submitted manuscripts by liberating authors from the stultified structure of NHSTP thinking thereby eliminating an important obstacle to creative thinking.
I’ve seen the fixation on statistical significance be a big block in presenting results in business settings. I can’t count the times where I’ve had to explain, especially with “big data” sets, that just because something is statistically significant doesn’t mean it’s practically significant. How much of the cult of statistical significance comes from the choice of words? Presumably the same is true in the social science setting; at least in both cases you have people with some statistical education and who are generally used to looking at numbers but are not statisticians or otherwise specialists in a quantitative field.
However this may be a bit of an overreaction. To say “thou shalt not do X” could be just as restrictive as “thou shalt always do X”.
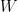 and the husband’s earnings
and the husband’s earnings  ; we’re interested here in the distribution of the random variable
; we’re interested here in the distribution of the random variable  . (Of course it’s difficult to write out the distribution of
. (Of course it’s difficult to write out the distribution of ![[-10000, -5000], [-5000, +5000]](https://s0.wp.com/latex.php?latex=%5B-10000%2C+-5000%5D%2C+%5B-5000%2C+%2B5000%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![[+5000, +10000]](https://s0.wp.com/latex.php?latex=%5B%2B5000%2C+%2B10000%5D&bg=ffffff&fg=000000&s=0&c=20201002) . The second interval is twice as wide as the others – so we’d expect twice as many couples to be in that middle bin as the ones on either side of it.
. The second interval is twice as wide as the others – so we’d expect twice as many couples to be in that middle bin as the ones on either side of it. divides the number of digits of
divides the number of digits of 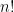 are: 1, 22, 23, 24, 266, 267, 268, 2712, 2713, 27175, 27176, 271819, 271820, 271821, 2718272, 2718273, 27182807, 27182808, 271828170, 271828171, 271828172, and so on. (For example,
are: 1, 22, 23, 24, 266, 267, 268, 2712, 2713, 27175, 27176, 271819, 271820, 271821, 2718272, 2718273, 27182807, 27182808, 271828170, 271828171, 271828172, and so on. (For example,  has
has  digits. This supposedly comes from a column of Martin Gardner, “Factorial Oddities”, which I don’t have.
digits. This supposedly comes from a column of Martin Gardner, “Factorial Oddities”, which I don’t have. doing there? But there’s a simple explanation. Recall Stirling’s approximation:
doing there? But there’s a simple explanation. Recall Stirling’s approximation: 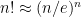 . Taking log base 10, we get
. Taking log base 10, we get  . But for
. But for 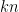 digits, we need
digits, we need  . Thus
. Thus 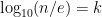 . Solving for
. Solving for  .
. .
. 1, so if what I’d just done worked exactly we’d have 2718281 in the sequence, But we have 2718272 and 2718273, eight and nine less than that. This is because we could have used the more accurate verison of the approximation:
1, so if what I’d just done worked exactly we’d have 2718281 in the sequence, But we have 2718272 and 2718273, eight and nine less than that. This is because we could have used the more accurate verison of the approximation: 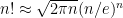 . Thus
. Thus  is a slight underapproximation.
is a slight underapproximation.