This made the rounds last week: Substantiating Fears of Grade Inflation, Dean Says Median Grade at Harvard College Is A-, Most Common Grade Is A, from the Harvard Crimson.
Now, I agree that an A-minus is probably too high here. (Although Jordan Ellenberg says we shouldn’t worry about grade inflation.)
But does it really matter that the most common grade is an A? Consider, say, a situation where there is a “triangular” distribution of grades: 5 A, 4 B, 3 C, 2 D, and 1 F. The most common grade is an A, but the median is a B (and the mean is 2.67 on a 4.0 scale, a B-minus). If there are more grade categories the same thing happens – if we have a triangular distribution of grades such as this, the median grade  of the way up — about midway between a B-minus and a B on the 4.0 scale usual in the US. The mean grade would be
of the way up — about midway between a B-minus and a B on the 4.0 scale usual in the US. The mean grade would be 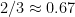 of the way up the scale. More generally, say grades are in the interval [0, 1]. If grades are beta-distributed with parameters 1 and
of the way up the scale. More generally, say grades are in the interval [0, 1]. If grades are beta-distributed with parameters 1 and 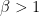 (my triangular idea is just the Beta(1, 2) distribution) then the modal grade will be 1 but the mean and median will be a good bit lower,
(my triangular idea is just the Beta(1, 2) distribution) then the modal grade will be 1 but the mean and median will be a good bit lower,  and
and  respectively.
respectively.
(I’m not claiming that grades are beta-distributed, but that’s not a bad model for something that’s often thought of as being roughly normally distributed but has to be contained within an interval.)
Basically, modes don’t tell you much.
