A question from Republic of Math:
The fit in this plot looked a bit off to me – it seems like it should be a log, not a square root. (But of course a log is just a zeroth power…) For those who aren’t familiar, the Collatz conjecture is as follows: given an arbitrary positive integer, if it’s even, divide it by 2, and if it’s odd, multiply by 3 and add 1. Repeat. As far as we know, you always end up at 1. For example, say we start with 7; then we get
7, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1
So why should this be true? Consider only the odd numbers in the sequence. In the previous sequence those are
7, 11, 17, 13, 5, 1
where we get each number by taking three times the previous one, plus one, and then dividing by 2 as many times as we can. We can figure that half the time we’ll divide by 2 once, a quarter of the time we’ll divide by 2 twice, and so on; on average we’ll divide by 2 twice. So each number in this sequence should be, on average, about three-quarters of the previous one, and each step in this sequence corresponds to three steps in the previous sequence (one tripling and two halvings). Thus each step on average multiplies by  and it should take
and it should take  steps to get from
steps to get from  down to 1. Call this
down to 1. Call this  where
where  .
.
This heuristic argument is in, for example, the review paper of Lagarias; this online HTML version of the same paper gives the additional remark that the stopping time of the sequence is conjectured to be asymptotically normally distributed with mean and variance both on the order of  . (The constant is different there; that’s because Lagarias goes directly from
. (The constant is different there; that’s because Lagarias goes directly from  to
to  if is odd.)
if is odd.)
Let’s define a function  to be the number of iterations in this process needed to get to 1. For example look at the trajectory for 7 above; it takes 16 iterations to get to 1, so
to be the number of iterations in this process needed to get to 1. For example look at the trajectory for 7 above; it takes 16 iterations to get to 1, so  . Similarly for example
. Similarly for example  (the trajectory is 4, 2, 1) and
(the trajectory is 4, 2, 1) and  (the trajectory is 6, 3, 10, 5, 16, 8, 4, 2, 1). This is the sequence A006577 in the OEIS. Then the original question is about the function
(the trajectory is 6, 3, 10, 5, 16, 8, 4, 2, 1). This is the sequence A006577 in the OEIS. Then the original question is about the function  . But since “most” numbers less than $\latex n$ have their logarithms near $\latex \log n$, that sum can be approximated as just
. But since “most” numbers less than $\latex n$ have their logarithms near $\latex \log n$, that sum can be approximated as just  or $\latex C \log n$.
or $\latex C \log n$.
And indeed a logarithmic model is the better fit (red in the plot below; blue is a power law – in both cases I’ve just fit to the range  )
)

Sadly, we don’t recover that constant 10.42… the red curve is  and the blue curve is
and the blue curve is  . But it’s not like you’d expect asymptotic behavior to kick in by 5000 anyway.
. But it’s not like you’d expect asymptotic behavior to kick in by 5000 anyway.

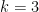



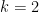
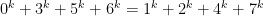





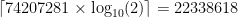 digits – call this
digits – call this  , so I don’t have to write it out over and over again. Therefore it contains
, so I don’t have to write it out over and over again. Therefore it contains  seven-digit strings.
seven-digit strings. . Any “slot” of seven digits has probability
. Any “slot” of seven digits has probability  of holding any particular string. If all the slots were independent, then the distribution of the number of different seven-digit strings which appear would be
of holding any particular string. If all the slots were independent, then the distribution of the number of different seven-digit strings which appear would be 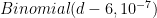 , which is essentially
, which is essentially 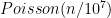 . But they are not quite independent – some overlap. The extent of the overlap is very small, though, so we needn’t worry, and we proceed with the approximation. This works out to about 0.8929, exactly the proportion that Radcliffe reports. Similarly for eight-digit strings we get a probability of 0.2002.
. But they are not quite independent – some overlap. The extent of the overlap is very small, though, so we needn’t worry, and we proceed with the approximation. This works out to about 0.8929, exactly the proportion that Radcliffe reports. Similarly for eight-digit strings we get a probability of 0.2002.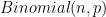 with
with  – we flip a “biased coin” with probability 0.8929 of success to determine if each string, from 0000000 to 9999999, appears in our random string. Then this has mean $np$ and standard deviation
– we flip a “biased coin” with probability 0.8929 of success to determine if each string, from 0000000 to 9999999, appears in our random string. Then this has mean $np$ and standard deviation 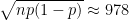 – so we should expect the last three or four digits of any realization to be different from those of the mean. In general,
– so we should expect the last three or four digits of any realization to be different from those of the mean. In general, 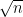 – so in realizations of it we expect half the digits to be “right” (i. e. the same as in
– so in realizations of it we expect half the digits to be “right” (i. e. the same as in 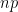 ) and half to be wrong. (I swear I’ve read before about this rule of thumb of half the digits being right, but this is hard to Google.)
) and half to be wrong. (I swear I’ve read before about this rule of thumb of half the digits being right, but this is hard to Google.) ;
;