John D Cook wrote, following the latest episode of Kevin Stroud’s History of English podcast, that if a consonant at the end of a word is doubled, it’s probably S, L, F, or Z. It appears that some elementary school teachers teach a “doubled final consonant rule” that is roughly the converse of this: “If a short vowel word or syllable ends with the /f/, /l/, /s/, or /z/ sound, it usually gets a double f, l, s, or z at the end.”
That sounds right to me. Some other consonants seem doubleable but relatively rarely – G, N, and R came to mind, although the only words I could think of that actually end in those doubled are “egg”, “inn”, and “err” respectively. Those are probably instances of the three-letter rule, whereby “content words” tend to have at least three letters. (Walmart has a store-brand of electronics onn. (sic), as well.)
Cook writes: “These stats simply count words; I suspect the results would be different if the words were weighted by frequency.” Challenge accepted. Peter Norvig has some useful data, including “The 1/3 million most frequent words, all lowercase, with counts.”
counts = read_delim('https://norvig.com/ngrams/count_1w.txt', delim = '\t', col_names = c('word', 'count'))
counts %>% mutate(ult = str_sub(word, -1),
penult = str_sub(word, -2, -2)) %>%
filter(!(ult %in% c('a', 'e', 'i', 'o', 'u'))) %>%
mutate(double = (ult == penult)) %>%
group_by(ult) %>%
summarize(double = sum(double*count), all = sum(count)) %>%
mutate(pct_double = double/all * 100)
Result is as follows; the counts in columns “double” and “all” are numbers of words out of the “trillion-word” data set. So over one out of every four words ending in L, in ends in double-L; only 0.02% of words ending in Y end in double-Y. Norvig’s word counts come from the 2006 trillion-word data set from Alex Franz and Thorsten Brants at the Google Machine Translation Team coming from public web pages.
# A tibble: 21 × 4
ult double all pct_double
<chr> <dbl> <dbl> <dbl>
1 l 6881678966 24910774907 27.6
2 z 49070005 684008846 7.17
3 s 3928825545 84468484631 4.65
4 f 734823669 16788706705 4.38
5 x 85268118 3108416171 2.74
6 c 128294648 6294874635 2.04
7 j 7948601 390085263 2.04
8 b 49690347 2690064550 1.85
9 p 98252923 6905211199 1.42
10 d 460147985 47335849371 0.972
11 m 95423709 11371100313 0.839
12 w 52402066 6908722748 0.758
13 q 2645593 456516943 0.580
14 t 295347877 52262740152 0.565
15 n 238685552 49492910349 0.482
16 v 3478513 1084201734 0.321
17 g 51208927 19948325553 0.257
18 r 58629294 38947533393 0.151
19 k 8943711 8602400357 0.104
20 h 13449679 14180781466 0.0948
21 y 7451329 35763181677 0.0208
The count for “L” is so high because of words like “all” and “will”. It turns out in this corpus my intuition about G, N, and R being plausible is spectacularly wrong. We can also get the five most common words ending in each double letter:
counts %>% mutate(ult = str_sub(word, -1),
penult = str_sub(word, -2, -2)) %>%
filter(!(ult %in% c('a', 'e', 'i', 'o', 'u'))) %>%
mutate(double = (ult == penult)) %>% filter(double) %>% group_by(ult) %>% mutate(rk = rank(-count)) %>% filter(rk <= 5) %>% summarize(paste(word, collapse = ', ')) %>% print(n = 21)
giving the following table:
# A tibble: 21 × 2
ult top5
<chr> <chr>
1 b bb, phpbb, webb, bbb, cobb
2 c cc, acc, gcc, fcc, icc
3 d add, dd, odd, todd, hdd
4 f off, staff, stuff, diff, jeff
5 g egg, gg, digg, ogg, dogg
6 h hh, ahh, ahhh, ohh, hhh
7 j jj, hajj, jjj, bjj, jjjj
8 k kk, dkk, skk, fkk, kkk
9 l all, will, well, full, small
10 m mm, comm, hmm, hmmm, dimm
11 n inn, ann, lynn, nn, penn
12 p pp, app, ppp, supp, spp
13 q qq, qqqq, qqq, sqq, haqq
14 r rr, err, carr, starr, corr
15 s business, address, access, class, press
16 t scott, matt, butt, tt, hewlett
17 v vv, vvv, rvv, vvvv, cvv
18 w www, ww, aww, libwww, awww
19 x xxx, xx, xnxx, xxxx, vioxx
20 y yy, yyyy, nyy, yyy, abbyy
21 z jazz, buzz, zz, jizz, azz
and S, L, F, and Z do emerge as the only letters where the resulting words aren’t just junk. The rules seems to loosen for names (Matt, Scott, Hewlett; Ann, Lynn, Penn; Cobb). The data set betrays its internet origins here, with phpbb and libwww being relatively common.
I’ve found the pattern at the end of the code block above,
group_by(ult) %>% mutate(rk = rank(-count)) %>% filter(rk <= 5) %>% summarize(paste(word, collapse = ', '))
useful in practice for giving a quick summary of a table where there are many possible values of a second variable for each value of a first variable, and we just want to show which are most common.


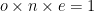
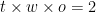

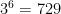 possibilities. If we weight each of these possibilities equally, it amounts to assuming that each game is a win for A, a draw, or a loss for A with equal probability. I wouldn’t want to do this with hand, but by computer it’s easy enough. As usual, using
possibilities. If we weight each of these possibilities equally, it amounts to assuming that each game is a win for A, a draw, or a loss for A with equal probability. I wouldn’t want to do this with hand, but by computer it’s easy enough. As usual, using 

