Another reason Clinton lost Michigan: Trump was listed first on the ballot, by Josh Pasek, University of Michigan. (Disclaimer: I went to middle and high school with Pasek.) From the blog post: “The best estimate of the effect of being listed first on the ballot in a presidential election is an improvement of the first-listed individual’s vote share of 0.31%.” Trump was listed first on the Michigan ballot, because the governor of Michigan is Republican. This study is based on elections in California, which randomizes the order of the candidates on the ballot by precinct. Here’s a preprint of the paper (Pasek, J., Schneider, D., Krosnick, J. A., Tahk, A., Ophir, E., & Milligan, C. (2014). Prevalence and moderators of the candidate name-order effect evidence from statewide general elections in California. Public Opinion Quarterly, 78(2), 416-439.).
Clinton also would have won if the map of the United States looked slightly different. If you want to play around with this yourself, you can redraw the states using the tool by Kevin Hayes Wilson. Move Camden County, New Jersey into Pennsylvania and Lucas County, Ohio (i. e. roll back the Toledo War, which was a thing) into Michigan, and Clinton wins. Each of these counties is adjacent to the state it’s being moved into. Here’s the resulting map.
I’m pretty sure that two is the minimal number of counties that have to be moved to get a Clinton win, under the constraint that the counties in each state have to remain geographically contiguous. Clinton starts out needing 37 more EV. and the only way to get that by flipping just one state is to flip Texas; but no state adjacent to Texas went blue. There is a way to make Clinton win that involves moving one county into another state – namely, move Los Angeles County, California into Texas – but that doesn’t seem to be in the spirit.)
The natural question, then, if we want to know how much “unfairness” is due to the electoral college, is something like this: given the actual voting results, and some “random” partitioning of the US into states, what is the probability of a Trump (or Clinton) win? But what does a “random” partitioning of the US into states even mean? It seems difficult to define this, given that we don’t have a huge number of alternate histories to run, but I’d imagine we’d want to preserve facts like:
- some states have many more people than others, but no state is much smaller in population than the average congressional district;
- more populous states tend to be more urban (this is relevant since the electoral college helps low-population states, and one party is more represented in urban areas);
- states are geographically relatively compact (unlike, say, Congressional districts in some states)
But in the end this is an academic question, because we don’t get to redraw the states. (Can you imagine the gerrymandering?)
 , which can be written in one line:
, which can be written in one line: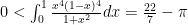 But I’ve always found this one unsatisfying because what does that integral have to do with
But I’ve always found this one unsatisfying because what does that integral have to do with  anyway? As it turns out,
anyway? As it turns out, 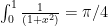 . But let’s say I’m a purist and think that
. But let’s say I’m a purist and think that  , which can be shown by explicit computation:
, which can be shown by explicit computation:  and
and  .
.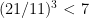 . This is what happens when you do arithmetic in your head…
. This is what happens when you do arithmetic in your head… and in particular
and in particular  by the
by the 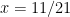 gives
gives  .
. .
. . This is a geometric fact that goes back to
. This is a geometric fact that goes back to  .
.