From Zach Wener-Fligner at Quartz, <a href=”http://qz.com/288707/everything-you-think-you-know-about-the-news-is-probably-wrong/”>Everything you think you know about the news is probably wrong</a>, based on <a href=”https://www.ipsos-mori.com/researchpublications/researcharchive/3466/Perceptions-are-not-reality-10-things-the-world-gets-wrong.aspx”>this Ipsos MORI study</a> of online panels in fourteen countries: Australia, Belgium, Canada, France, Germany, Hungary, Italy, Japan, Poland, South Korea, Spain, Sweden, Great Britain and the United States of America. Ipsos MORI compute an “index of ignorance” – but to some extent this may just be an index of innumeracy.
For example, the average American, when asked, guessed that 24% of girls aged 15-19 give birth each year. The actual value is 3%. In every country surveyed people were off by a factor of at least five. I’d posit that this is not a question of being uniformed so much as innumerate. If 24% of girls aged 15-19 give birth each year, and nobody gives birth before 15, then the average number of children of a woman at age twenty would be 1.2. Do people seriously think the average twenty-year-old woman has more than one child? I doubt it.
The other questions were percentage of Muslims (most people overestimate), Christians (most underestimate), immigrants (overestimate), percentage who voted in the last major election (underestimate), percentage “unemployed and looking for work” (overestimate), and life expectancy of a child born in 2014 (pretty much right on).
One of these numbers is not like the others. We’ll all die someday, and we all have some idea of how long people live, so we naturally get this right. But the others are asking for percentages, and I don’t think most people could tell the difference between “10% of people have this trait” and “20% of people have this trait” just by guessing. South Koreans and Japanese overestimate the number of Christians – and those are the two countries on this list in which Christians are a minority. I wonder, if you looked at the estimates people gave for a lot of these percentages, if they’d show a peak at 50%, the thought process being “well, people with trait X exist, but not everybody has trait X, so what’s a number in between? I’ll just pick the simplest rational number between 0 and 1.”
I’m a bit puzzled about the unemployment numbers, though. These are generally fairly loudly trumpeted in the media, so I’d expect people at least give estimates in line with those ranges, and yet, for example, the US guess is 32 percent. (The percentage of people “unemployed and looking for work” is actually lower than the unemployment rate, by definition, as the unemployment rate is the percentage of people in the labor force who are looking for work – the unemployment rate has the same numerator and a smaller denominator.) Even if people think about the experiences of those close to them instead of the public at large, on average this shouldn’t change things unless unemployed people happen to have lots of friends and family who take these surveys.
I’d also be interested to see how estimates correlated with political views. For example, are people who think there are more immigrants more likely to be anti-immigration? Do people who think the unemployment rate is higher support policies that would stimulate their nations’ economies?
 . The question is to write the largest possible such product (ideally without doing the multiplication explicitly).
. The question is to write the largest possible such product (ideally without doing the multiplication explicitly). . But how can you move around the digits between the factors? Which is larger,
. But how can you move around the digits between the factors? Which is larger,  or $\latex 754 \times 82$? The trick here is to rewrite as
or $\latex 754 \times 82$? The trick here is to rewrite as  and
and  , and recall that of two pairs of numbers with the same sum, the ones closer together have a larger product. That is,
, and recall that of two pairs of numbers with the same sum, the ones closer together have a larger product. That is, 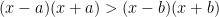 if and only if
if and only if 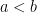 . Since
. Since  , we can conclude that
, we can conclude that  .
. is larger. But now we can switch the 2 and the 4 by the same sort of logic:
is larger. But now we can switch the 2 and the 4 by the same sort of logic:  and so
and so  . This, it turns out, is the best we can do, as we can check by brute force – but how do we know this holds up generally? I haven’t used the differences between digits explicitly, only their ordering, so perhaps everything only depends on the order of the digits. Let’s let our digits be
. This, it turns out, is the best we can do, as we can check by brute force – but how do we know this holds up generally? I haven’t used the differences between digits explicitly, only their ordering, so perhaps everything only depends on the order of the digits. Let’s let our digits be 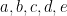 , with
, with  . Then there are just ten possible products to look at if we’re trying to find the largest once, since the digits in each factor have to be increasing:
. Then there are just ten possible products to look at if we’re trying to find the largest once, since the digits in each factor have to be increasing: .
. I mean
I mean 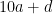 , and so on.)
, and so on.) , for example, to show that it’s larger than $cde \times ab$; the inequality in the middle follows from
, for example, to show that it’s larger than $cde \times ab$; the inequality in the middle follows from 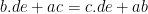 . If I’m not mistaken, any time two of these ten products differ by just switching two letters we can prove an inequality between them. And after a seriously grungy case analysis (which I won’t bore you all with) I believe we get that
. If I’m not mistaken, any time two of these ten products differ by just switching two letters we can prove an inequality between them. And after a seriously grungy case analysis (which I won’t bore you all with) I believe we get that  is always the largest product. In any case, for this particular problem there are only
is always the largest product. In any case, for this particular problem there are only  possibilities so you could check by brute force. (Not a good exercise for people who you’re trying to teach to think about place value, but also not a bad programming exercise…)
possibilities so you could check by brute force. (Not a good exercise for people who you’re trying to teach to think about place value, but also not a bad programming exercise…)