A list of famous quotes about statistics. I actually used the Fisher quote, “To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of”, in an e-mail to a colleague today; I believe I first saw this quote in John Cook’s blog.
Facebook on age gaps in relationships
It’s been a while. I blame the holidays and some Secret Big News.
Facebook’s data science team has an interesting post on the age difference between two people in a relationship. Fun fact: the average age difference in same-sex couples (of either sex) is much larger than that in opposite-sex couples. Why? I can think of two reasons:
(1) the size of the pool of potential mates is smaller for same-sex couples than for opposite-sex couples. Therefore individuals in same-sex couples have to compromise more on other dimensions, like age.
(2) the idea that both partners in a relationship should be of the same age is “conventional”, and people who are in same-sex relationships (an unconventional choice, if strictly for numerical reasons) are likely to make unconventional choices about other aspects of their relationships as well.
One possible way to find evidence for (1): is the difference between same-sex and opposite-sex couples larger in areas where there are less same-sex couples? If so, this is evidence for the “compromise” hypothesis – where there are less same-sex couples there ought to be more compromising along other dimensions. (Similarly, are the members of same-sex couples more different on other dimensions – such as educational status, race, religion, and so on – in areas with less same-sex couples?) It seems more difficult to find a way to test (2).
100 years of crosswords
It’s the hundredth anniversary of the publication of the first crossword – check out today’s Google Doodle.
On a related note, crosswords are possible in English (or other natural languages) because a large enough proportion of the possible strings of letters are actual words. I learned this from chapter 18 of Information Theory, Inference, and Learning Algorithms by David Mackay (which you can read online). (Chapter 19 is about why to have sex, from an information-theoretic point of view.) And Dr. Fill is a crossword-solving program by Matthew Ginsberg which did not win the 2012 American Crossword Puzzle Tournament.
This made the rounds last week: Substantiating Fears of Grade Inflation, Dean Says Median Grade at Harvard College Is A-, Most Common Grade Is A, from the Harvard Crimson.
Now, I agree that an A-minus is probably too high here. (Although Jordan Ellenberg says we shouldn’t worry about grade inflation.)
But does it really matter that the most common grade is an A? Consider, say, a situation where there is a “triangular” distribution of grades: 5 A, 4 B, 3 C, 2 D, and 1 F. The most common grade is an A, but the median is a B (and the mean is 2.67 on a 4.0 scale, a B-minus). If there are more grade categories the same thing happens – if we have a triangular distribution of grades such as this, the median grade 
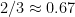
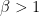


(I’m not claiming that grades are beta-distributed, but that’s not a bad model for something that’s often thought of as being roughly normally distributed but has to be contained within an interval.)
Basically, modes don’t tell you much.
This week’s best statistics joke
This week’s best statistics joke: median rent.
State-to-state migration in the US
Here’s an interactive visualization showing state-by-state migrations within the US, by Chris Walker.
It’s not possible to reconstruct all migrations between states from this chart. The data are available in a spreadsheet that the American Community Survey (part of the Census Bureau) puts out.
In case you’re wondering, the (ordered) pair of states with the most movement is California to Texas. Tyler Cowen would have forecasted that, but it’s worth pointing out that this is hardly surprising as California and Texas are the states with the largest population. Relative to the population of the target state, Californians are most likely to move to Nevada, Washington, Arizona, and Oregon; Texans are most likely to move to Oklahoma, New Mexico, Louisiana, and Arkansas. For non-American readers, I just said “people are most likely to move to nearby states”, which is the sort of thing that it’s easy to lose track of in my position living in San Francisco and generally surrounded by transplants from far away.
If I could spare the time I’d try to visualize this – which pairs of states have greater flows between them than would be expected from their populations and the distance between them? The prototype here would probably be the flow from the northeastern states to Florida.
Weekly links for November 4
Jeremy Kun on the UCB1 algorithm for the multi-armed bandit problem. (Incidentally, none of the authors of the paper introducing the algorithm were affiliated with UCB – it stands for “upper confidence bound”.)
What is the sound of sorting?
Colm Mulcahy has a magic trick based on polydivisible numbers.
Swapping clothes instead of kidneys
A friend of mine just got a job at Swapdom, which organizes multi-way swaps of clothes among people who don’t want them anymore and want to rejuvenate their wardrobes. You can search the community and point to things you would like and things you’d happily give up in exchange for them, and they find swaps that actually work. In particular they orchestrate multi-way swaps (A gives to B, which gives to C, which gives to A, or even longer cycles).
If you’re Alvin Roth, you can win a Nobel* Prize for this stuff. At least if it’s kidneys being traded instead of clothes. The Nobel foundation has both popular and technical expositions of his work in market design; the largest kidney swap in history, a few months ago, involved 28 kidneys.
(Disclaimer: I don’t actually know what’s going on behind the scenes with Swapdom’s algorithm; my friend is not a technical person.)
Weekly links for October 28
The return of weekly links:
Paul Zorn on communicating mathematics.
The traveling salesman problem on NOVA.
A blob navigates a chemical maze.
Statistics done wrong, a guide to the most common statistical errors.
Cloudflare’s primer on elliptic curve cryptography
Cloudflare (a web security company) has a primer on elliptic curve cryptography and its uses for privacy and security online. Quick version: RSA cryptography relies on the fact that multiplying integers is easy but factoring them is hard. Elliptic curve cryptography relies on the fact that there’s a group law for elliptic curves over the integers mod n, and applying that group law repeatedly (exponentiation) is easy but determining how many times that law was applied (taking the discrete logarithm) is hard.
