From the March 11, 2022 “Riddler”:
We’re playing a game where you have to pick four whole numbers. Then I will roll four fair dice. If any two of the dice add up to any one of the numbers you picked, then you win! Otherwise, you lose.
For example, suppose you picked the numbers 2, 3, 4 and 12, and the four dice came up 1, 2, 4 and 5. Then you’d win, because two of the dice (1 and 2) add up to at least one of the numbers you picked (3).
To maximize your chances of winning, which four numbers should you pick? And what are your chances of winning?
Some first thoughts:
- You want numbers that are common as the sums of two dice – middling numbers, numbers near seven.
- The problem has a reflection symmetry. The dice values
win with the target sums
if and only if the dice values
win with the target sums
.
Putting these together, a symmetric set of middling numbers seems likely to be the best target set – something like 5, 6, 8, 9. This is a nasty case analysis, but it’s easy to do by brute force in R.
library(tidyverse)
dice_and_targets = expand.grid(d1 = 1:6, d2 = 1:6, d3 = 1:6, d4 = 1:6,
t1 = 2:12, t2 = 2:12, t3 = 2:12, t4 = 2:12) %>% filter(t1 < t2 & t2 < t3 & t3 < t4) %>%
mutate(s12 = d1 + d2, s13 = d1 + d3, s14 = d1 + d4,
s23 = d2 + d3, s24 = d2 + d4, s34 = d3 + d4)The data frame `dice_and_targets` has a row for every possible combination of dice results (d1 … d4) and targets (t1 … t4), and the sums of the dice (s12 … s34). It’s a big data frame, with 
Let’s take a look at a sample of this data frame, consisting of 10 randomly selected rows:
set.seed(1)
dice_and_targets$idx = sample(nrow(dice_and_targets))
dice_and_targets %>% filter(idx <= 10) %>% select(-idx)
d1 d2 d3 d4 t1 t2 t3 t4 s12 s13 s14 s23 s24 s34
1 1 2 3 5 2 3 5 8 3 4 6 5 7 8
2 4 1 6 5 2 3 4 9 5 10 9 7 6 11
3 2 3 4 5 3 6 7 9 5 6 7 7 8 9
4 2 1 5 6 3 5 8 9 3 7 8 6 7 11
5 1 6 4 6 2 6 9 10 7 5 7 10 12 10
6 3 4 4 6 3 6 7 11 7 7 9 8 10 10
7 2 2 4 2 4 8 10 11 4 6 4 6 4 6
8 1 2 3 5 2 3 4 12 3 4 6 5 7 8
9 2 6 6 1 2 6 8 12 8 8 3 12 7 7
10 1 6 3 6 6 8 11 12 7 4 7 9 12 9Consider, for example, the first row. In this case we roll 1, 2, 3, and 5; the targets are 2, 3, 5, and 8; the pairwise sums are 1+2 = 3, 1+3 = 4, 1+5 = 6, 2+3 = 5, 2+5 = 7, and 2+6 = 8; and we win the game, in fact three times over, since the pairwise sums include three of the targets, namely 3, 5, and 8.
Next we can work out which rows win, leveraging some bitwise operations because how often do I get a chance to use these?
dice_and_targets = dice_and_targets %>% mutate(target_bits = bitwOr(bitwOr(2^t1, 2^t2), bitwOr(2^t3, 2^t4)))
dice_and_targets = dice_and_targets %>%
mutate(sum_bits = bitwOr(bitwOr(bitwOr(2^s12, 2^s13), bitwOr(2^s14, 2^s23)), bitwOr(2^s24, 2^s34)))
dice_and_targets = dice_and_targets %>%
mutate(win = bitwAnd(target_bits, sum_bits) > 0)In this case target_bits has the bit corresponding to 

sum_bits has the bit corresponding to 

bitwAnd(target_bits, sum_bits) has a nonzero bit if and only if we have a winning combination.
Let’s look at those randomly selected rows, now with the wins figured out:
dice_and_targets %>% filter(idx <= 10) %>% select(-idx)
d1 d2 d3 d4 t1 t2 t3 t4 s12 s13 s14 s23 s24 s34 target_bits sum_bits win
1 1 2 3 5 2 3 5 8 3 4 6 5 7 8 300 504 TRUE
2 4 1 6 5 2 3 4 9 5 10 9 7 6 11 540 3808 TRUE
3 2 3 4 5 3 6 7 9 5 6 7 7 8 9 712 992 TRUE
4 2 1 5 6 3 5 8 9 3 7 8 6 7 11 808 2504 TRUE
5 1 6 4 6 2 6 9 10 7 5 7 10 12 10 1604 5280 TRUE
6 3 4 4 6 3 6 7 11 7 7 9 8 10 10 2248 1920 TRUE
7 2 2 4 2 4 8 10 11 4 6 4 6 4 6 3344 80 TRUE
8 1 2 3 5 2 3 4 12 3 4 6 5 7 8 4124 504 TRUE
9 2 6 6 1 2 6 8 12 8 8 3 12 7 7 4420 4488 TRUE
10 1 6 3 6 6 8 11 12 7 4 7 9 12 9 6464 4752 TRUE
In the first row, here, target_bits is 
sum_bits is 
bitwAnd(target_bits, sum_bits) (not shown) is 
You might get the idea that it’s impossible to lose from this sample. We got a little lucky here: mean(dice_and_targets$win) returns 0.874018. If you pick a random roll of four dice and four random targets out of 2, 3, …, 12, one of the pairwise sums will be in the target set 87% of the time.
But we want to know which target set makes a win most likely.
win_counts_by_target = dice_and_targets %>% group_by(t1, t2, t3, t4) %>% summarize(wins = sum(win)) %>% arrange(desc(wins))
head(win_counts_by_target)
> head(win_counts_by_target)
# A tibble: 6 x 5
# Groups: t1, t2, t3 [5]
t1 t2 t3 t4 wins
<int> <int> <int> <int> <int>
1 4 6 8 10 1264
2 2 6 8 10 1246
3 4 6 8 12 1246
4 4 6 7 9 1238
5 5 7 8 10 1238
6 4 7 8 9 1236
There we go! And not a loop in sight.
Once I have the 4, 6, 8, 10 target set it’s easy to come up with that number 1264. Consider just the dice that show even numbers – you win if there are at least two of these and they’re not all showing 6. Similarly you win if there are at least two odd dice and they’re not all showing 1. So the losing combinations are
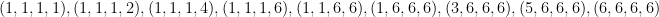
and their rearrangements, of which there are 32.
Incidentally, my initial guess (5, 6, 8, 9) wasn’t bad – it wins 1228 times out of 1296, good enough for 14th place out of the 330 possible target sets. And the very worst target set? It’s (2, 3, 11, 12). No surprise there, although even that one wins 776 times out of 1296, nearly 60% of the time.
 . So we need to find positive integers x, y, z such that x + y + z = 100 and
. So we need to find positive integers x, y, z such that x + y + z = 100 and 

 . The three big factors – the two 7s and the 11 – look like they’ll be worrisome. So let’s spread them out: let x and y both be multiples of 7, and let z be a multiple of 11. To get them to add up to 100, we need to find a multiple of 7 and a multiple of 11 that add up to 100; it’s easy to find 44 and 56. So z = 44.
. The three big factors – the two 7s and the 11 – look like they’ll be worrisome. So let’s spread them out: let x and y both be multiples of 7, and let z be a multiple of 11. To get them to add up to 100, we need to find a multiple of 7 and a multiple of 11 that add up to 100; it’s easy to find 44 and 56. So z = 44.  , so x and y must be 21 and 35.
, so x and y must be 21 and 35.  will have many factors, and many ways to be written as a product of three integers, making it more likely that one of those will have the right sum.
will have many factors, and many ways to be written as a product of three integers, making it more likely that one of those will have the right sum. .
. 
 . This is nonstandard, but the result looks like a clock, so it’s easier to visualize:
. This is nonstandard, but the result looks like a clock, so it’s easier to visualize:
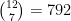 ways that we could pick 7 out of the 12 holes. To generate a list of these I can use the following R function:
ways that we could pick 7 out of the 12 holes. To generate a list of these I can use the following R function:

