The sequence A025280 in the Encyclopedia of Integer Sequences gives the “complexity of 

I’ll abbreviate sums of 1s by the numbers they sum to. So the complexity of 4 is 4 (you can write it as 



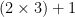

There are some variants of it: A005245 doesn’t allow exponentiation, and A091334 allows subtraction. (This is a practical difference: 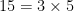
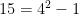

R. K. Guy, in Some suspiciously simple sequences, suggests that the complexity of n is bounded above by some mutliple of log n.
Can we get some asymptotic trend? The following code in R produces the multiplicative and exponential complexities of the integers from 1 up to 10000. (R is probably not the ideal language for this, since it’s essentially a number-theoretic problem, but I want to make boxplots later.)
n = 10^4;
commul=rep(0,n); commul[1]=1; commul[2]=2;
for(i in 2:n){m=i;
m = min(m, commul[1:floor(i/2)] + commul[(i - 1):(i - floor(i/2))]);
for(j in 2:sqrt(i)) {
if (i%%j == 0) {m = min(m,commul[j]+commul[i/j]) };
commul[i]=m}
}
comexp=rep(0,n); comexp[1]=1; comexp[2]=2;
for(i in 3:n){m=i;
m = min(m, comexp[1:floor(i/2)] + comexp[(i - 1):(i - floor(i/2))]);
for(j in 2:sqrt(i)) {
if (i%%j == 0) {m = min(m,comexp[j]+comexp[i/j]) };
for(j in 2:log(i,2)) {
base = log(i,j);
if (abs(base-round(base)) comexp[i]=m}
}
We know the complexity of an integer i is bounded above by i. First we run over the pairs 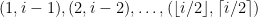

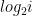
So we end up with the multiplicative complexity and the exponential complexity of each integer. And we can plot them:

(Multiplicative complexity is in black; exponential complexity is in red.)
Indeed they both seem to grow logarithmically. As you’d expect exponential complexities are smaller, and there are some quite noticeable downward spikes at large powers: for example the exponential complexity of 4096 is 9 (it’s 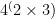

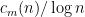




We can then make a boxplot for the numbers 
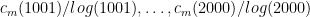


Is there some limiting distribution? Can we say, for example, that in the limit half of integers have multiplicative complexity less than 3.1 times their natural logarithm? I don’t know.

I’ve been looking into the upper bound on this sequence (whose function I will call A(n)) on my own. Using big-O notation (described at end), I have been able to prove that it is O(log(n)^2), but I have not been able to get that down to O(log(n)), although I have not shown that to be impossible.
To get it to O(log(n)^2), I express an as 2^0+2^1+2^2…2^log2(n), committing certain terms, effectively representing it as a binary number. Because n can be achieved by ommiting terms from the above sequence, we know that
A(n)<=(2+0)+(2+1)+(2+2)…+(2+log2(n)).
A(n)<=2*log2(n)+(0+1+2…log2(n))
A(n)0, b such that
for all x>b
f(x)<=k*g(x)