An issue of sampling bias: doctors think people are sicker than they actually are, because most of the patients they see are sick. This is also known as the “clinician’s illusion”. Say you’re a doctor, and you have six “well” patients that you see once a year and one “sick” patient that you see once a month. Then out of your eighteen annual appointments, two-thirds will be with “sick” patients even though only one-seventh of your patients are sick! Patricia and Jacob Cohen wrote about this in 1984; here’s a recent explanation from a web site about addiction.
This is also a hazard of teaching: and perhaps related to the “80-20” rule: you spend 80 percent of your time dealing with 20 percent of the students. Certainly grading feels this way to me, since I teach classes where the questions generally have “right” answers, and I give partial credit – my impression of the average student is probably less favorable than the actual average student. The ones who get things right are easy to grade, so they take up less time than the ones who get things wrong, since I have to read their wrong answers carefully to decide where they went wrong. Perhaps grading feels less like this on more open-ended assignments. I’d be interested to hear.
Another educational example is that by simply making all classes at an institution the same size, one can reduce the average class size experienced by students without actually having to hire more faculty. Say your institution has one class of thirty students and one of sixty. Then if you pick a student uniformly at random, one-third will say “there are thirty students in my class” and two-thirds will say “there are sixty students in my class”, for an average of (1/3)(30)+(2/3)(60)=50. If you rebalance the classes to have forty-five students in each class, then the average class size experienced by students is 45. (The average class size experienced by students, by the way, is always greater than or equal to the average class size experienced by instructors, with equality if and only if all classes are the same size.)
Finally: how many children, including you, did your mother have? The average, averaging over women, is somewhere around 2 in the US. But say that the proportion of women having i children is 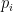

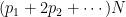

Let 




I can tell you from all the time I’ve spent as TA for 370/371/116 and teaching 170 at Penn…it’s worse for more open-ended assignments. It’s often a lot harder to figure out where something went wrong, and so you spend much more time on the student who make mistakes than on the ones who don’t. Results may vary, but for these, my numbers were definitely worse than 80-20 (though on the plus side, more opportunities to get a balanced look because the good students are more likely to talk to you outside of class to learn more random stuff)
The example of this I think of most is that it explains why one seems to be driving most often in the more congested of two lanes of traffic.
The general term is “size bias”. For any distribution X with non-negative range, density [or probability mass function] f(x) and finite mean mu, the size bias X* of X has density x f(x) / mu. Then, for example, if X is the distribution of class sizes (resp. number of children) as seen by the faculty (resp. mothers), X* is the distribution seen by the students (resp. children).
It’s amusing to calculate the distribution of X* when X is Poisson, Binomial, or Geometric and then explain the new distribution intuitively based on known properties of X. When X has an Exponential distribution, the distinction between X and X* is known as the Waiting Time Paradox.
Another similar principle is that even if 50% of trips are less than 6 miles, whereas only 5% of trips are greater than 30 miles, you’ll cover more distance (and potentially spend more time) on the longer trips. (Assuming that the 0-6 mile trips average 3 miles each).
Fascinating. This also looks a bit like the “friendship paradox” that most people have fewer friends than their friends have, on average (http://en.wikipedia.org/wiki/Friendship_paradox). Or is it a different sampling problem.
I’ve seen people refer to the friendship paradox in a similar context, but it doesn’t feel exactly the same as this set of problems.
The friendship paradox is similar, but it is not a simple size biasing since it depends on more than just the distribution of friend numbers– it depends on the entire structure of the “friendship graph”.
But the general principle still applies: people with lots of friends are more likely to be friends of yours than people with few friends, so randomly picking a person will, on average, yield a friend number smaller than that obtained by averaging the friend numbers for the friends of a randomly chosen person.