Rick Wicklin asks: which initials are most common?
This is followed with a simulation of the birthday problem. There are 676 different pairs of initials, so you might expect that to have probability 1/2 of two people in a group having the same initials, you’d need 31 people. This is the smallest 

A question that Wicklin doesn’t try to answer, though, is whether first and last initials are independent. In Wicklin’s data set of 4,502 employees at SAS (where he works), 403 people have first name starting with M, and 224 people have last name starting with L. 14 have the initials ML. From those marginal frequencies you’d expect 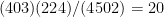
inits = read.csv("C:/Users/Michael/Desktop/blog/initials.csv")
inits = inits[with(inits,order(I1,I2)),]
x=matrix(inits$COUNT,26,26,T)
A chi-squared test for independence (chisq.test(x)) gives 

chisq.test(x, simulate.p.value=T, B=10^6)
simulates a million contingency tables with the distributions of first and last initials given in Wicklin’s data — assuming those are independent — and reports the proportion of those tables which have χ2 larger than 915.4.
When I ran this simulation I got p = 0.005138, still significant but much less extreme than the former results. And as Wicklin points out, SAS is ethnically heterogeneous; it might be that in homogeneous populations first and last initials are independent, and dependence comes from aggregation. For an extreme example, say that there are two kinds of people, red and blue; red people’s first and last initials are independent and uniformly distributed over the first half of the alphabet, and blue people’s over the second half. But I don’t have a big ethnically homogeneous data set to test that on.

Look at an Ohio voter file for a random county. That’s a giant cross-sectional database for names.
The Monte Carlo method you mention above is interesting to me. If I am concerned about bias against my null hypothesis, would reporting the percentage of Monte Carlo simulations reporting a lower P value be appropriate in an academic paper? It’s a Master’s level public policy thesis, not intended to be published so I am just hoping to avoid doing something foolish.
I have ran Monte Carlo simulations using randomly generated independent variables and I have strong evidence of bias against the null using a chi2 test. I’d love to keep the tests and just report the monte Carlo rankings in addition to the p-values. Any advice would be appreciated. Thanks.