Jason Rosenhouse and Laura Taalman have written an excellent book, Taking Sudoku Seriously. Despite the title, this is not primarily a puzzle book; rather it uses Sudoku, and the idea that mathematicians are essentially puzzle solvers, as a gateway into explaining to the general reader what it is that mathematicians do. The book actually contains very few standard Sudoku puzzles but a large number of variations on the standard theme. This is more interesting than standard Sudoku, I find; once you learn how to do standard Sudokus you essentially are just executing an algorithm mindlessly.
(Don’t borrow this book from a library, as I did, if you intend to do the puzzles, unless you’re okay with hogging a copy machine for a while; also, even then, some puzzles in this book involve color in a meaningful way.)
Some Sudoku-related facts from this book that I found interesting:
How many filled-in Sudoku squares are there? The authors begin by carefully working through counting “Shidoku” puzzles; this is like Sudoku, but 4-by-4 instead of 9-by-9. The method is essentially to fill in the upper left 2-by-2 square; then finish the first row and first column. If we start with
then there are three ways to complete this board. Each of these represents 96 possible Shidokus, obtained by switching the third and fourth columns, or not; switching the third and fourth rows, or not; and permuting the numbers 1, 2, 3, 4. So there are 288 possible Shidokus. But many of these are equivalent; it turns out that there are only two essentially different Shidoku puzzles:
| 1 |
2 |
3 |
4 |
| 3 |
4 |
1 |
2 |
| 2 |
1 |
4 |
3 |
| 4 |
3 |
2 |
1 |
and
| 1 |
2 |
3 |
4 |
| 3 |
4 |
1 |
2 |
| 2 |
3 |
4 |
1 |
| 4 |
1 |
2 |
3 |
and all others can be reached from these by various symmetries, including relabeling the digits, permutation of certain rows, columns, or blocks, and rotations or reflections. These symmetries form the Shidoku group; unfortunately the orbits of its action on the set of Shidokus are of different sizes! (There are 96 Shidoku puzzles equivalent to the first one above, and 192 equivalent to the second, for a total of 288.
Determining the number of Sudoku puzzles is harder. There are 948,109,639,680 ways to fill in the first three rows of a Sudoku, satisfying the Sudoku constraints. (See the Wikipedia article on the mathematics of Sudoku.) This actually gives a nice heuristic argument for the total number of ways to fill in a Sudoku. There are  ways to fill in the first three rows of a Sudoku if we just force each row to have nine different numbers and ignore the constraint on the blocks. So if we fill in the first three rows by filling each row with a permutation chosen uniformly at random, then the probability of satisfying the block constraint is
ways to fill in the first three rows of a Sudoku if we just force each row to have nine different numbers and ignore the constraint on the blocks. So if we fill in the first three rows by filling each row with a permutation chosen uniformly at random, then the probability of satisfying the block constraint is  ; call this number
; call this number  . Now imagine filling all nine rows of a Sudoku with permutations chosen uniformly at random; there are
. Now imagine filling all nine rows of a Sudoku with permutations chosen uniformly at random; there are  ways to do this. But now the probability that the top three blocks satisfy the block constraint is ; the same is true for each of the three rows of blocks and each of the three columns. If we assume these constraints are independent, which they’re not, then we estimate that the total number of 9-by-9 squares with each row containing nine different numbers, and each set of three blocks forming a row or column being valid in Sudoku, is $(9!)^9 p^6$. But these are just filled Sudokus, and that number is about $6.6 \times 10^{21}$. Perhaps coincidentally, but perhaps not, the actual number of Sudokus is about $6.7 \times 10^{21}$, as shown by Felgenhauer and Jarvis; the heuristic is due to Kevin Kilfoil.
ways to do this. But now the probability that the top three blocks satisfy the block constraint is ; the same is true for each of the three rows of blocks and each of the three columns. If we assume these constraints are independent, which they’re not, then we estimate that the total number of 9-by-9 squares with each row containing nine different numbers, and each set of three blocks forming a row or column being valid in Sudoku, is $(9!)^9 p^6$. But these are just filled Sudokus, and that number is about $6.6 \times 10^{21}$. Perhaps coincidentally, but perhaps not, the actual number of Sudokus is about $6.7 \times 10^{21}$, as shown by Felgenhauer and Jarvis; the heuristic is due to Kevin Kilfoil.
How are sudoku puzzles constructed? One way to do it is to set a “mask” — a set of squares within the puzzle which will be filled in — and then populate randomly and count the number of solutions. Then make random changes to the numbers filling in this mask, generally but not always reducing the number of solutions, (The authors state that something like this was used to form the puzzles in the book by Riley and Taalman, No-Frills Sudoku.)
Sudoku puzzles can be encoded in terms of graph colorings. Each square in Sudoku becomes a node, and we draw an edge between two vertices that can’t be filled with the same number; then the question is to extend a partial coloring of the Sudoku graph to a full coloring.
But they can also be encoded in terms of polynomials For these purposes we’ll play Sudoku with the numbers -2, -1, 1, 2, 3, 4, 5, 6, 7. Let each cell of the Sudoku be represented by a variable. Then for each cell we have an equation  latex x_1 + x_2 + \cdots + x_9 = 25, x_1 x_2 \cdots x_9 = 10080$
latex x_1 + x_2 + \cdots + x_9 = 25, x_1 x_2 \cdots x_9 = 10080$
encoding the fact that each of the nine numbers is contained in the region exactly once. (Why not use the usual numbers, 1 through 9? Because there is another set of nine integers that has sum 45 and product 362880; can you find it?)
I’ll close with an extended quote that I think bears repeating (pp. 115-116):
Your authors have been teaching mathematics for quite some time now, and it has been our persistent experience that this lesson [that hard puzzles are more interesting to solve than easy puzzles], obvious when pondering Sudoku puzzles, seems to elude students struggling for the first time with calculus or linear algebra. When presented with a problem requiring only a mechanical, algorithmic solution, the average student will dutifully carry out the necessary steps with grim determination. Present instead a problem requiring an element of imagination or one where it is unclear how to proceed, and you must brace yourself for the inevitable wailing and rending of garments.
This reaction is not hard to understand. In a classroom there are unpleasant things like grades and examinations to consider, not to mention the annoying realities of courses taken only to fulfill a requirement. Students have more on their minds than the sheer joy of problem solving. They welcome the mechanical problems precisely because it is clear what is expected of them. A period of frustrated confusion can be amusing when working on a puzzle, because there is no price to be paid for failing to solve it. The same experience in a math class carries with it fears of poor grades.
Finally, if you don’t have time to spare to read the whole book, look at Taalman’s article Taking Sudoku Seriously. If you like your math in podcast form, listen to Sol Lederman’s interview with Rosenhouse and Taalman. If you could care less about math but want books of Sudoku: No Frills Sudoku (standard Sudoku, but starting with an astonishingly low 18 clues each), Naked Sudoku (Sudoku variants with no starting numbers), Color Sudoku (more graphically interesting).
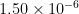
ways; here order matters.
.
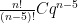
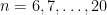

 over
over 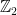 , and noting that it has exactly two solutions.) Finally, rock beats scissors. If the missing symbol is scissors or paper we just permute the symbols.
, and noting that it has exactly two solutions.) Finally, rock beats scissors. If the missing symbol is scissors or paper we just permute the symbols. . Then clearly
. Then clearly  — in each case the spacy sets are just the empty set and the one-element subsets.
— in each case the spacy sets are just the empty set and the one-element subsets. . How can you make a spacy subset of
. How can you make a spacy subset of 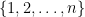 ? Well, any spacy subset of
? Well, any spacy subset of  is a spacy subset of
is a spacy subset of 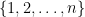 which does not contain $lates n$, and there are
which does not contain $lates n$, and there are 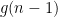 of those. And any spacy subset of
of those. And any spacy subset of  . There are $g(n-3)$ of those. Any spacy subset of $\latex \{1, 2, \ldots, n\}$ either contains or does not contain
. There are $g(n-3)$ of those. Any spacy subset of $\latex \{1, 2, \ldots, n\}$ either contains or does not contain  , and $2$ (for notational ease I’m dropping the braces$. The spacy subsets of
, and $2$ (for notational ease I’m dropping the braces$. The spacy subsets of  are
are 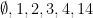 . So the spacy subsets of
. So the spacy subsets of  are $\emptyset, 1, 2, 3, 4, 14$ (from the spacy subsets of
are $\emptyset, 1, 2, 3, 4, 14$ (from the spacy subsets of  ) and
) and 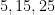 (from adding a 5 to each spacy subset of
(from adding a 5 to each spacy subset of  .)
.) , which is my net winnings on a single roll; we have
, which is my net winnings on a single roll; we have  (the probability of rolling 10),
(the probability of rolling 10), 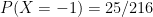 (the probability of rolling 9), and
(the probability of rolling 9), and  (the probability of rolling something else).
(the probability of rolling something else). . So after n rolls, for large n, the distribution of my net winnings is approximately normal with mean 0.0093n and variance 0.2406n, by the central limit theorem.
. So after n rolls, for large n, the distribution of my net winnings is approximately normal with mean 0.0093n and variance 0.2406n, by the central limit theorem.
 . So
. So  . From this I usually conclude in class (somewhat facetiously) that the players of these dice games had too much time on their hands. (In practice I suppose that the observation that 10 coming up more often than 9 came from tabulation of many players playing this game, not a single player playing many thousands of times.)
. From this I usually conclude in class (somewhat facetiously) that the players of these dice games had too much time on their hands. (In practice I suppose that the observation that 10 coming up more often than 9 came from tabulation of many players playing this game, not a single player playing many thousands of times.)
 . And there are other senses in which there are “effectively” only about fifteen possible first initials. For example, if $p_i$ is the probability that a random person’s first initial is the $i$th letter, then $(\sum_i p_i^2)^{-1} \approx 0.0710$; this number, roughly
. And there are other senses in which there are “effectively” only about fifteen possible first initials. For example, if $p_i$ is the probability that a random person’s first initial is the $i$th letter, then $(\sum_i p_i^2)^{-1} \approx 0.0710$; this number, roughly  , is the probability that two people chosen at random from the population has the same birthday.
, is the probability that two people chosen at random from the population has the same birthday. pairs of people. Each pair has probability $\sum_i p_i^2 = 0.0710$ of coincidence. So the expected number of coincidences is
pairs of people. Each pair has probability $\sum_i p_i^2 = 0.0710$ of coincidence. So the expected number of coincidences is 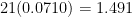 . If we assume that the distribution of the number of coincidences is Poisson (which it’s not!), the probability of at least one coincidence is
. If we assume that the distribution of the number of coincidences is Poisson (which it’s not!), the probability of at least one coincidence is  . Not bad. (The same model gives
. Not bad. (The same model gives 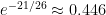 for the uniform distribution, where the correct answer is 0.413.
for the uniform distribution, where the correct answer is 0.413.