Rick Wicklin at the SAS blog writes on the frequency of bigrams in an English corpus. In English: how often does a pair of letters, such as “TH” or “QZ”, appear in English text? This is a follow-up to a previous post on the frequency of letters in an English corpus and builds on an analysis by Peter Norvig of letter frequencies in the Google Books corpus.
The post on bigrams ends with a heatmap of the distribution of bigrams. It’s what Howard Wainer calls an Alabama first graphic – the letters are in alphabetical order. Now, if there’s ever a time that called for alphabetical order, it’s when ordering the alphabet. But what can we learn by putting the letters in another order?
The “heatmap” command in R does exactly this,hierarchically clustering both the rows and columns. (The command “hclust”, which does the clustering under the hood, does complete-linkage clustering by default.) If we cluster on log counts, we get the image below:
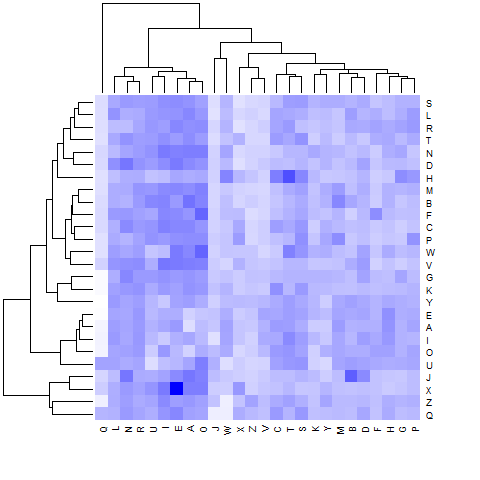
where first letters correspond to columns (listed along the bottom) and second letters to rows (listed along the right). More intense blue corresponds to more frequent bigrams, so this roughly replicates Wicklin’s heat map. Not surprisingly, the vowels end up together.
Alternatively, we can associate with each bigram a number which is its frequency divided by its expected frequency if adjacent letters were independent of each other. This number is greater than 1 (represented by a blue color below) if the letters like to be arranged that way, and less than 1 (red) if the letters don’t like this.
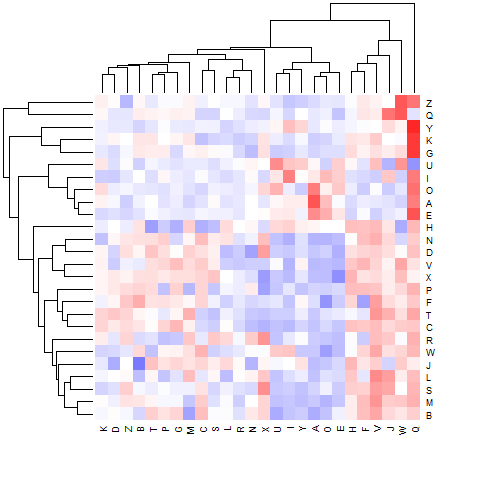
There are some clear color patterns, which could be useful in e. g. cryptography. For example, vowels tend to be preceded and followed by consonants (the blue patches in the upper left and lower center, respectively). Certain consonants (the ones at the right: H, F, V, J, W, Q) really don’t like to followed by other consonants, but other consonants (S, L, R, N) don’t mind. What else do you see?
Side note: the bonus round in Wheel of Fortune spots you the letters R, S, T, L, N, and E. But the most common five consonants are (in order) T, N, S, R, H; L is sixth. Why the discrepancy? This is brought up by Wicklin’s commenter Quentin. I’d add that under the current rules you’re allowed to then guess three more consonants and a vowel; for a while, if I remember correctly, the usual choices were C, D, M, and A. Those are the seventh, eighth, and ninth most common consonants, still omitting H. Ben Blatt, at Slate, suggests that B, G, H, O is better, in the sense that it will reveal more letters in a typical puzzle.
