From the Census Bureau via Slate, on the income gaps between opposite-sex married couples:
- in 3.9 percent of couples, the husband earns 5,000 to 9,999 more dollars (per year) than the wife;
- in 25.4 percent of couples, the husband earns within 4,999 dollars of the wife;
- in 2.8 percent of couples, the wife earns 5,000 to 9,999 more dollars than the husband.
(The rest of the couples have more than a 10,000-dollar differential.)
Something seems fishy here. Call the wife’s earnings 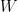


![[-10000, -5000], [-5000, +5000]](https://s0.wp.com/latex.php?latex=%5B-10000%2C+-5000%5D%2C+%5B-5000%2C+%2B5000%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[+5000, +10000]](https://s0.wp.com/latex.php?latex=%5B%2B5000%2C+%2B10000%5D&bg=ffffff&fg=000000&s=0&c=20201002)
But instead we have six to nine times as many. Any explanations? All I can think of to explain this phenomenon – if it’s real – is that there are a surprisingly large number of cases where the husband and wife do the same job (not just working at the same place, but actually doing the same thing, for the same pay)… but how many couples like that can there be? It seems more likely to be an artifact of how the survey works.

Your expectation that the middle one would have twice as many as the other bins assumes that men and women marry randomly with regard to income, and that incomes themselves have a uniform distribution. But “assortative mating” is a thing (couples meet in college, grad school, jobs, etc), and the individual income distribution itself (something like lognormal) will make incomes naturally clumped together a bit too. 25.4% may in fact be high, but you’d expect some clumping near 0 difference…
Disclaimer: I am a mathematician but not a statistician.
Intuitively, it seemed natural to me that the distribution near 0 would be higher (even assuming no correlation).
I tried to make this formal.
For example, suppose that both men and women’s income has the same uniform distribution say on [a,b]. Then, assuming no correlation, the distribution of the difference is an “upright triangle” with a maximum at 0 no?
If the original distribution itself has a central bulge, then this phenomean is amplified and the difference distribution gets an ever bigger bulge around 0.
Anyway, I may be missing something but it looks to me as though there is not much needing explaining, it suffices to assume that the distribution for both men and women have central bulges that are not too far apart from each other. (Again, this is even with no correlation. Correlation would amplify this even more.)
Self reporting of income to the census and joint-filing of taxes probably create some noise in this data.