Apparently students in the UK have been protesting against the following question on a GCSE math exam (see e. g. coverage at The Guardian):
There are n sweets in a bag. Six of the sweets are orange. The rest of the sweets are yellow. Hannah takes a random sweet from the bag. She eats the sweet. Hannah then takes at random another sweet from the bag. She eats the sweet. The probability that Hannah eats two orange sweets is 1/3. Show that n²-n-90=0.
The probability that the first sweet is orange is  . Now there are five orange sweets left out of
. Now there are five orange sweets left out of  , so the probability that the second sweet is orange, assuming that the first one is, is
, so the probability that the second sweet is orange, assuming that the first one is, is  . Therefore we need to solve
. Therefore we need to solve  . Multiplying it out gives
. Multiplying it out gives

and we can easily rearrange to get  . So
. So 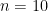 ; there are 10 sweets. (I guarantee you that a bunch of students went straight for the quadratic formula at this point – but you don’t have to, it’s easy to find two consecutive numbers that multiply to 90.) According to the BBC, setters of the exam point out that this was supposed to be one of the more difficult questions, “targeted at students aiming for A and A* grades”.
; there are 10 sweets. (I guarantee you that a bunch of students went straight for the quadratic formula at this point – but you don’t have to, it’s easy to find two consecutive numbers that multiply to 90.) According to the BBC, setters of the exam point out that this was supposed to be one of the more difficult questions, “targeted at students aiming for A and A* grades”.
There’s a question this reminds me of, of which I don’t recall the original source: there are r raspberry sweets and b blueberry sweets in a bag. You take two of them at random; the probability that they have the same flavor is exactly 1/2. What are possible values for r and b? (Okay, so I’ve heard it with “red” and “blue”, but let’s go with fruit flavors.) (Okay, so I’ve heard it with “red” and “blue”, but let’s go with fruit flavors.) See for example this Quora question. This one is a bit trickier, and depends on getting lucky and choosing the right parametrization of the problem. If the number of reds/raspberries is  and the number of blue(berries) is
and the number of blue(berries) is  , then we have
, then we have

the first term is the probability of drawing red-red and the second is the probability of drawing blue-blue. We can rewrite as

but that isn’t much of a help, to be honest. Solving for in terms of gives
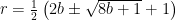
and if you happen to know the obscure piece of trivia that for integer , 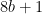 is a perfect square if and only if is triangular, then you can show that and must be two consecutive triangular numbers. For example
is a perfect square if and only if is triangular, then you can show that and must be two consecutive triangular numbers. For example  leads to the solutions
leads to the solutions  and
and 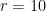 .
.
But if you use n = r + b, then is as pointed out at the Quora answer, 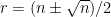 (with different notation) and this doesn’t require knowing anything obscure. Setting
(with different notation) and this doesn’t require knowing anything obscure. Setting  leads immediately to the solutions
leads immediately to the solutions  , for example. In general, to make this work out the number of sweets needs to be a perfect square.
, for example. In general, to make this work out the number of sweets needs to be a perfect square.
What if there are three colors of sweets? How can we choose the number of sweets of each color to make the probability of getting a match equal to one-third?
