The sequence A025280 in the Encyclopedia of Integer Sequences gives the “complexity of  : number of 1’s required to build using [addition, multiplication, and exponentiation]”. Let’s call this the “exponential complexity” and denote it by
: number of 1’s required to build using [addition, multiplication, and exponentiation]”. Let’s call this the “exponential complexity” and denote it by  .
.
I’ll abbreviate sums of 1s by the numbers they sum to. So the complexity of 4 is 4 (you can write it as  , which I’ll abbreviate as
, which I’ll abbreviate as  , or
, or  , which I’ll abbreviate as $2+2$. But the complexity of 6 is 5 (it’s
, which I’ll abbreviate as $2+2$. But the complexity of 6 is 5 (it’s  and so the complexity of 7 is 6 (it’s
and so the complexity of 7 is 6 (it’s 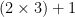 ). 36 has complexity 7, since it’s
). 36 has complexity 7, since it’s  .
.
There are some variants of it: A005245 doesn’t allow exponentiation, and A091334 allows subtraction. (This is a practical difference: 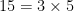 , and 15 has complexity 8 if subtraction isn’t allowed, but
, and 15 has complexity 8 if subtraction isn’t allowed, but 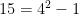 gives a complexity of 7 if subtraction is allowed. Not allowing subtraction makes computation easier, though — by only allowing addition, multiplication, and exponentiation we compute everything in terms of small numbers. Call the version in terms of addition and multiplication only
gives a complexity of 7 if subtraction is allowed. Not allowing subtraction makes computation easier, though — by only allowing addition, multiplication, and exponentiation we compute everything in terms of small numbers. Call the version in terms of addition and multiplication only  , for “multiplicative complexity”.
, for “multiplicative complexity”.
R. K. Guy, in Some suspiciously simple sequences, suggests that the complexity of n is bounded above by some mutliple of log n.
Can we get some asymptotic trend? The following code in R produces the multiplicative and exponential complexities of the integers from 1 up to 10000. (R is probably not the ideal language for this, since it’s essentially a number-theoretic problem, but I want to make boxplots later.)
n = 10^4;
commul=rep(0,n); commul[1]=1; commul[2]=2;
for(i in 2:n){m=i;
m = min(m, commul[1:floor(i/2)] + commul[(i - 1):(i - floor(i/2))]);
for(j in 2:sqrt(i)) {
if (i%%j == 0) {m = min(m,commul[j]+commul[i/j]) };
commul[i]=m}
}
comexp=rep(0,n); comexp[1]=1; comexp[2]=2;
for(i in 3:n){m=i;
m = min(m, comexp[1:floor(i/2)] + comexp[(i - 1):(i - floor(i/2))]);
for(j in 2:sqrt(i)) {
if (i%%j == 0) {m = min(m,comexp[j]+comexp[i/j]) };
for(j in 2:log(i,2)) {
base = log(i,j);
if (abs(base-round(base)) comexp[i]=m}
}
We know the complexity of an integer i is bounded above by i. First we run over the pairs 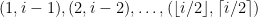 and compute the sums of their complexities; then we find factors of
and compute the sums of their complexities; then we find factors of  by trial division and do the same for products; then we check to see if is a perfect square, cube, and so on up to
by trial division and do the same for products; then we check to see if is a perfect square, cube, and so on up to 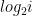 th power.
th power.
So we end up with the multiplicative complexity and the exponential complexity of each integer. And we can plot them:

(Multiplicative complexity is in black; exponential complexity is in red.)
Indeed they both seem to grow logarithmically. As you’d expect exponential complexities are smaller, and there are some quite noticeable downward spikes at large powers: for example the exponential complexity of 4096 is 9 (it’s 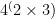 ) while its multiplicative complexity is 24 (as
) while its multiplicative complexity is 24 (as  ). If you divide out the logarithms — that is, plotting n against
). If you divide out the logarithms — that is, plotting n against 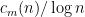 or
or  – all the black points lie between two horizontal line (around 2.8 and 3.6), and all the red points appear to lie below some horizontal line as well. There can’t be a horizontal line that all the red points lie above, other than the x-axis — if n has multiplicative complexity bounded above by c log n, then
– all the black points lie between two horizontal line (around 2.8 and 3.6), and all the red points appear to lie below some horizontal line as well. There can’t be a horizontal line that all the red points lie above, other than the x-axis — if n has multiplicative complexity bounded above by c log n, then  will have exponential complexity bounded above by
will have exponential complexity bounded above by  . But powers and numbers very near them will be sparse, so perhaps almost all integers have exponential complexity above some logarithmic bound.
. But powers and numbers very near them will be sparse, so perhaps almost all integers have exponential complexity above some logarithmic bound.

We can then make a boxplot for the numbers  ; one for
; one for 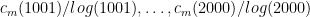 ; and so on, in groups of 1000. We can do the same for the exponential complexities.
; and so on, in groups of 1000. We can do the same for the exponential complexities.


Is there some limiting distribution? Can we say, for example, that in the limit half of integers have multiplicative complexity less than 3.1 times their natural logarithm? I don’t know.
 people are in a bar, sitting around a round table. A certain person pays for the first round of drinks. The person to their right pays for the second round. The person two people to the right of that person pays for the third round. In general, whoever paid for the nth round, the person n people to their right pays for the (n+1)st round.
people are in a bar, sitting around a round table. A certain person pays for the first round of drinks. The person to their right pays for the second round. The person two people to the right of that person pays for the third round. In general, whoever paid for the nth round, the person n people to their right pays for the (n+1)st round.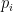 . Then if there are N total mothers, there are
. Then if there are N total mothers, there are  people in families of i children. The total number of children is
people in families of i children. The total number of children is 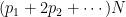 . So the average family size, averaging over children, is
. So the average family size, averaging over children, is
 be the mean number of children per woman, and let
be the mean number of children per woman, and let  be the variance; then this is
be the variance; then this is  , or
, or  . Again, the mean as experienced by the children is substantially larger than the mean as experienced by the parents.
. Again, the mean as experienced by the children is substantially larger than the mean as experienced by the parents.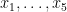 such that their mean and the mean of their squares are both integers. (Alternatively, their sum and the sum of their squares were both multiples of 5.) What are the chances of that?
such that their mean and the mean of their squares are both integers. (Alternatively, their sum and the sum of their squares were both multiples of 5.) What are the chances of that?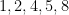 , so their sum is
, so their sum is  and their sum-of-squares is
and their sum-of-squares is  , both divisible by 5.
, both divisible by 5. . In fact one-fifth of the squares are divisible by 5; two-fifths are one more than a multiple of five; two-fifths are one less than a multiple of five.
. In fact one-fifth of the squares are divisible by 5; two-fifths are one more than a multiple of five; two-fifths are one less than a multiple of five.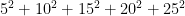 . This happens with probability
. This happens with probability  .
. . This happens with probability
. This happens with probability 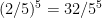 .
. .
. . The probability of this is the number of ways of choosing which of our five integers is one more than a multiple of 5 and which is one less — that’s
. The probability of this is the number of ways of choosing which of our five integers is one more than a multiple of 5 and which is one less — that’s  — times the probability of getting a square that’s one more than a multiple of five, then one that’s one less, then three multiples of 5, which is $(2/5)(2/5)(1/5)^3 = 4/5^5$, for a total of $80/5^5$.
— times the probability of getting a square that’s one more than a multiple of five, then one that’s one less, then three multiples of 5, which is $(2/5)(2/5)(1/5)^3 = 4/5^5$, for a total of $80/5^5$. . The probability of this is
. The probability of this is  .
.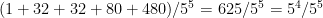 , or exactly one-fifth! Is there a simple argument for this?
, or exactly one-fifth! Is there a simple argument for this?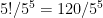 , or that all five have the same remainder, which happens with probability
, or that all five have the same remainder, which happens with probability  . And these add up to…
. And these add up to… 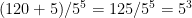 .
. . However,
. However, 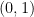 and
and 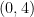 both have probability $6/125$, and
both have probability $6/125$, and  and
and  both have probability $4/125$. I have no idea why things work out this way, as this is just the result of a brute-force calculation.
both have probability $4/125$. I have no idea why things work out this way, as this is just the result of a brute-force calculation.



