Alright, this is too easy. From my hometown newspaper: Good Friday, Passover overlap.
Passover is supposed to start around the full moon, and last for a week.
Easter is supposed to fall on the Sunday after the full moon.
So this should happen pretty frequently. The calculations involved are both complicated enough that I’ll just jump straight to simulation. Here’s a quick implementation of Gauss’s computus in R:
easter = function(year){
a = year %% 19;
b = year %% 4;
c = year %% 7;
k = floor(year/100);
p = floor((13+8*k)/25);
q = floor(k/4);
M = (15 - p + k - q) %% 30;
N = (4 + k - q) %% 7;
d = (19*a + M) %% 30;
e = (2*b + 4*c + 6*d + N) %% 7;
day = 22 + d + e;
if( d == 29 && e == 6) {day = 50}
if( d == 28 && e == 6 && ((11*M+11) %% 30) < 19 ) {day = 49}
day;
}
This code inputs the year and outputs the date of Easter as a day of March; for example this year, Easter is April 8, or “March 39”, and easter(2012) outputs 39.
Conway has a formula for the date of Passover. Actually it’s a formula for the date of Rosh Hashanah; if (the first day of) Rosh Hashanah falls on September M in a given Gregorian calendar year, then the first day of Passover in the same Gregorian year is March M + 21. In both cases the beginning is actually at sundown the previous evening. For example this year the first day of Rosh Hashanah is September 17, 2012 (actually sundown on the 16th) and Passover begins on March 17 + 21 = 38, or April 7 (actually sundown on April 6).
First one computes a tentative Rosh Hashanah date based on the full moon. (This is actually a rational number; it’s convenient for later purposes to keep the fractional part.
roshhashanah.t = function(year) {
g = (year %% 19) + 1;
n = floor(year/100) - floor(year/400) - 2 + 765433/492480*((12*g) %% 19) + (year %% 4)/4 - (313*year + 89081)/98496;
}
The rational constants are here because the Hebrew calendar incorporates a fractional approximation to the time between full moons.
But Rosh Hashanah is sometimes postponed by a day or even two because it falls on a day of the week that is inconvenient. (For example, one does not want Yom Kippur to fall on a Friday or Sunday, which works out to not having Rosh Hashanah on a Wednesday or Friday.) So we need a day-of-week function, namely Zeller’s congruence:
dayofweek = function(year, month, day) {
if (month<3) {year = year-1; month = month+12}
x = day + floor((month+1)*26/10) + year + floor(year/4) + 6*floor(year/100) + floor(year/400);
x %% 7;
}
This returns 0 for Saturday, 1 for Sunday, …, 6 for Friday. Now we implement the postponements:
roshhashanah = function(year) {
rh = roshhashanah.t(year);
dow = dayofweek(year,9,floor(rh));
if(dow == 1 | dow == 4 | dow == 6) {rh = rh+1};
frac = rh-floor(rh);
g = (year %% 19) + 1;
if(dow == 2 & frac >= 23629/25920 & (12*g %% 19) > 11) {rh = rh+1};
if(dow == 3 & frac >= 1367/2160 & (12*g %% 19) > 6) {rh = rh+2};
rh;
}
Finally, to get the date of Passover (as a day in March):
passover = function(year) {roshhashanah(year) + 21};
So how often does the current coincidence happen? Let’s consider a thousand-year window centered on 2000. Generate the dates for Easter and Passover in that period:
E = easter(1500:2499)
P = rep(0,1000); for(i in 1500:2499){P[i-1499]=passover(i)}
Then table(P-E) gives a table of the date of the first day of Passover relative to the date of Easter. This year we have -1: the first day of Passover is Saturday, April 7, while Easter is Sunday, April 8. The table is as follows:
| difference |
-8 |
-7 |
-5 |
-3 |
-1 |
0 |
23 |
25 |
27 |
28 |
30 |
| frequency of difference |
12 |
101 |
234 |
236 |
228 |
20 |
27 |
49 |
48 |
23 |
22 |
In particular the situation we have this year occurs in 228 years of this thousand-year window, almost a quarter of the time! This is actually more often than I expected — I was thinking a bit under one year in seven, basically the one-seventh of the time when Passover starts on a Friday night, except somewhat less because sometimes the Christian and Jewish calculations pick out different full moons. But the Hebrew calendar postponement rules mean that Passover can only start on certain days of the week. You can see that even in this table — the difference of -2 never occurs, for example, because that would mean Passover starts on a Friday (i. e. Thursday night), which it can’t.
April 11, 2012: there seem to be some bugs in this code that lead its results to not agree with those from other tables. I’ll fix this at some point; for the time being please don’t rely on what’s here for anything serious.
 and the standard deviation of the number of heads from B is
and the standard deviation of the number of heads from B is  ; so in standardized terms, maybe B is more likely?
; so in standardized terms, maybe B is more likely?

 . Then we can find the posterior probability of having picked coin B, given 5 heads:
. Then we can find the posterior probability of having picked coin B, given 5 heads:
 heads in
heads in  tosses can be computed similarly, and it’s
tosses can be computed similarly, and it’s .
.
 case this is
case this is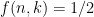 ? If
? If  ; rearranging this is
; rearranging this is  . Taking logs we get
. Taking logs we get  and so
and so 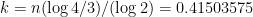 , slightly less than
, slightly less than 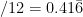 . If the proportion of heads is greater than 0.41503575 then guess coin
. If the proportion of heads is greater than 0.41503575 then guess coin  ; if it’s smaller than guess coin
; if it’s smaller than guess coin  .
.