I was looking at the list of US cities by population on Wikipedia yesterday, because I noticed that Sunnyvale, a suburb of San Jose that I had occasion to go to yesterday, had a surprisingly large population of 140,095. There are a lot of places like this in California — despite having about 12% of US population, it has 64 of the 275 largest cities (all those with population above 100,000), or about 23%.
And among those 275 cities there are three pairs with the same population in the 2010 Census:
- Fargo, North Dakota and Norwalk, California, both at 105,549
- Arvada, Colorado and Ventura, California, both at 106,433
- Aurora, Illinois and Oxnard, California, both at 197,899
Of course census data shouldn’t actually be taken to be exact. But how many pairs like this would we expect?
The starting point here is Zipf’s law for cities, or the rank-size rule. This rule states that the nth largest city in a region will have population 1/n times that of the largest city. As it turns out, this isn’t quite true for the structure of cities in the US, but they do roughly follow a power law. If we regress log(population) against log(rank), we get the regression line
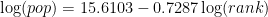
or, if we exponentiate both sides,

For example, we predict that the hundredth-largest city should have population 

Because I don’t want to rewrite these numbers over and over, I’m going to rewrite that as 



The expected number of cities having population exactly

Taking the derivative here is actually the crux of the analysis, so I’ll elaborate a bit. The expected number of cities having population at least p is 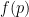



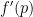

Roughly speaking, 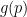
So now take this expected value, and figure that the actual number of cities of population p is a Poisson random variable with mean 

and I use the approximation 

but I’d rather do an integral instead of a sum, so we’ll approximate this as

Recalling that 
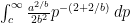
and doing the integral gives

Plugging in the values from above, c = 100000, a = 6018207, b = 0.7287, gives 0.1924. So the expected number of such coincidences is about one-fifth; in the 2010 census it was three.
If you compare data from 2000 the first such coincidence is at rank 467 – Royal Oak, MI and Bristol, CT both had population 60,062 that year. (Note: I scanned the data by eye, so it’s possible I missed something.) You expect to start seeing coincidences this far down; plugging in c = 60000 with the 2010 coefficients gives 1.3. (Properly speaking I should use the 2000 coefficients, but I’d have to compute them first.) So 2010 is probably unusual. Still, I can’t help but suspect that the Census might be fudging the data a little bit to make these cities tie so that the lower-ranked member of each couplet doesn’t complain…
I’m looking for a job, in the SF Bay Area. See my linkedin profile.

On the subject of “suprisingly big cities,” it’s kind of a fun exercise to go down the list and find out what’s the biggest US city you’ve never heard of. Mine was in California. (Biggest US university you’ve never heard of is also good.)
Mine was #87, in Texas, which is the state I expected it would be in before I started looking. (I suspect before I moved to California it would have been in California.) For universities, if you go by the Wikipedia list of universities I come up dry at #4, but I’m guessing that’s not the list you had in mind – do you know a better one?
It’s hard to find your articles in google. I found
it on 20 spot, you should build quality backlinks , it will help you to increase traffic.
I know how to help you, just type in google – k2 seo tips
Some advance algorithms also produce specific shipping cost or free shipping to specific customers depending upon their past
purchasing behavior. Many mobile operators promote 4G service
in the smartphones. Desktop remains where it is, of course but the growing usage
of smartphones can’t be overlooked when it comes to website designs for the year.
Just desire to say your article is as astonishing. The clarity for your publish is
just great and i could assume you’re knowledgeable in this subject.
Well together with your permission allow me to clutch your feed to keep updated with imminent post.
Thanks one million and please keep up the rewarding work.
Hey! This is my first visit to your blog! We are a group of volunteers and starting
a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You have
done a outstanding job!
I’m curious to find out what blog system you’re utilizing?
I’m having some minor security problems with
my latest site and I would like to find something more safeguarded.
Do you have any recommendations?
Click here