Let’s say for some reason we need to approximate decimal logarithms of some small primes. We know , so clearly . (All logarithms in this post are to base 10.) Can we approximate the logs of any other primes this way?
When I run through powers of small primes, the target that jumps out at me is
.
Taking logs of both sides gives
where . And of course we have , so this relation becomes
.
Are there other such relations? It turns out that there are finitely many numbers n such that n and n+1 have all their prime factors < 7 – apparently a conseuqence of the abc conjecture – so I just take the largest ones and derive relations like these. So I can derive similar relations from and $\log 4374 \approx \log 4375$, namely
and
This is a system of three (approximate) equations in three unknowns, and solving it in the usual way gives
.
while the true values are 0.30103, 0.47712, and 0.84510 – so this is good enough for three-place accuracy.
In practice, who wants to have a rational with 239 in the denominator as an approximation? More practical is the following:
remember (a fundamental fact of musical temperament).
That gives right away, , and then so . This is essentially I. J. Good’s singing logarithms, which exploits the fact that a lot of rational numbers with small numerator and denominator can be approximated as powers of , the fact on which our usual musical tuning system is based: , and a bit less accurately . (Musically these are the facts that the perfect fifth, major third, and minor seventh are the ratios 3/2, 5/4, and 7/4.).
Somehow toys just show up in this house, a phenomenon which I think is familiar to many parents. Some of them have icosahedral symmetry. Like this one.
Hard plastic icosahedron ball, with stars for vertices.
You can see that the designer was outlining the vertex of an icosahedron with that five-pointed star shape, but they couldn’t quite commit – the star points don’t actually point to the next vertex! (And no, they don’t turn.) You can get a better sense of the stars corresponding to the vertices of an icosahedron here:
There’s also this one, which is softer and has a couple of distinguished vertices antipodal to each other:
Soft icosahedron, with rattly bits at two antipodal vertices.
And this one which I bought for myself years ago, presumably in some sort of store that sold housewares. (Remember stores?)
Skeleton of an icosahedron.
The nice thing about this one is that you can see through it, which makes for some interesting photographic possibilities, such as this view where two antipodal vertices are aligned:
Skeleton of an icosahedron, photographed down an axis through two vertices.
and this view with that emphasizes a threefold rotational symmetry:
Skeleton of an icosahedron, emphasizing threefold symmetry.
Of course we have a soccer ball somewhere. You know what a soccer ball looks like, I’m not taking a picture.
I also use this as an avatar in various work systems that need one – these generally require small pictures and a face wouldn’t show up well, and it’s easier to pick out than the default in a lot of these systems which is just someone’s initials in a circle.
I had thought, for a few decades now, that STOP was the four-letter word with the most anagrams, with six: STOP itself, POST, POTS, TOPS, OPTS, SPOT. So of course when Josh Millard put out these STOP permutations signs, I had to buy one. It’s a limited edition of 24 stop sign prints, one for each permutation. (I opted for OPTS. As of this writing there are 18 still available; the 6 that have been bought are the five anagrams of STOP other than STOP itself, and SOTP.)
But then I had to check that claim. Peter Norvig has, meant to accompany a chapter on NLP, some word lists, of which I’ve used the enable1.txt list before for word puzzles. (I’m not sure who compiled this list.) We can put words into a canonical form by alphabetizing the letters – for example michael becomes acehilm, and stop becomes opst. Scrabble players call this an alphagram. Then to find the four-letter word with the most anagrams is just a matter of counting.
But wait! What is “seta”? Is “ates” really a thing – you can’t pluralize a verb like that! (“ate” appears to be Tagalog for “older sister”.) Perhaps the aers set, with seven anagrams, wins, but “sera” is technical (plural of serum), and as an American I have trouble recognizing “rase” as a legitimate spelling of “raze”. “lari” is a unit of money in Georgia (Tbilisi, not Atlanta) which I was unfamiliar with. And so on.
Fortunately Norvig also has a list of word frequencies (count_1w.txt), of the 332,202 most common words in a trillion-word corpus. (One of the perks of working at Google, I assume.) So we can read that in.
The most common words are the ones you’d expect. (2.3% of words are “the”.)
> head(freqs)
# A tibble: 6 x 2
word freq
<chr> <dbl>
1 the 23135851162
2 of 13151942776
3 and 12997637966
4 to 12136980858
5 a 9081174698
6 in 8469404971
And the least common words are… barely words. (I don’t know the full story behind this dataset.) So it seems reasonable that all “real” words will be here.
> tail(freqs)
# A tibble: 6 x 2
word freq
<chr> <dbl>
1 goofel 12711
2 gooek 12711
3 gooddg 12711
4 gooblle 12711
5 gollgo 12711
6 golgw 12711
Now we can attach frequencies to the words. There are too many words in the sets for a table to be nice, so we switch to plots.
words %>% left_join(alphagram_counts) %>%
filter(len == 4 & n >= 6) %>%
left_join(freqs) %>% arrange(alphagram, desc(freq)) %>%
select(alphagram, word, freq) %>% group_by(alphagram) %>%
mutate(rk = rank(desc(freq))) %>%
ggplot() + geom_line(aes(x=rk, y=log(freq/10^12, 10), group = alphagram, color = alphagram)) +
scale_x_continuous('rank within alphagram set', breaks = 1:8, minor_breaks = c()) +
scale_y_continuous('log_10 of word frequency', breaks = -8:-3, minor_breaks = c()) +
theme_minimal() + geom_text(aes(x=rk, y=log(freq/10^12, 10), color = alphagram, label = word)) +
ggtitle('Frequency of four-letter words with six or more anagrams')
And if we plot the frequency of each word against its rank in its own anagram set…
then we can see that the STOP set consists of much more common words than any of the others. (STOP isn’t even the most common of its own anagrams, which surprises me – that honor goes to POST. But when I was a small child STOP seemed much more common, because of the signs.) I’m surprised to see SERA so high; this is either an extremely technical corpus or (more likely) contamination from Spanish.
And here’s a similar plot for five letters. Here I’d thought the word with the most anagrams was LEAST (among “common” words, 6: TALES, STEAL, SLATE, TESLA, STALE) but it looks like SPARE wins with room to spare, even if you don’t buy that APRES is an English word.
How many borders between states are there in the United States?
Sure, you could get out a map and count them. Or you could estimate.
There are 48 contiguous states. The average state has six borders [citation needed], so that’s 288 borders, but we double-counted, so that’s 144. But we need to apply a bit of a haircut for those states that are around the edge. How many of those are there? Figure the US is roughly a 5-by-10 rectangle of states, so there are 30 states around the edge. 144 minus 30 is 114.
There are actually 109. In 1998 Thomas Holmes constructed a data set of those borders for a paper, The Effect of State Policies on the Location of Industry: Evidence from State Borders. I haven’t read the paper. It appears that it shows that there was more manufacturing activity on the “pro-business” (anti-union, has so-called right-to-work laws) side of a state border than on the “anti-business” (pro-union, doesn’t have so-called right-to-work laws) of the state border.
Some people like counting the borders they’ve crossed, as in this post at Twelve Mile Circle. That post includes a map by Jon Persky that gives 138 borders, but that includes 16 land crossings between contiguous US states and Canadian provinces; 8 between US states and Mexican states; two between Alaska and Canadian provinces; and three borders that can only be crossed by water (Maine – Nova Scotia, New York – Rhode Island, and Ohio – Ontario).
As for that fact that “the average state has six borders”, this is really a statement about planar graphs. From the map of the US, construct a planar graph by taking the 48 states as vertices and the state borders as edges. (You have a problem at Four Corners, which we’ll ignore.) Let E be the number of edges in the graph, and F its number of faces. Here a “face” corresponds to a place where three states meet, such as Pennsylvania-Maryland-Delaware or Georgia-Alabama-Tennessee. Then every edge meets two faces and, except for around the perimeter of the graph, every face has three edges, and thus . Euler proved , which we’ll approximate as . Thus , or rearranging ; the number of edges (state borders) is about three times the number of states.
From FiveThirtyEight’s “Riddler” feature: fill in this table with single-digit numbers, such that the entries in the margins are the products of the corresponding entries in the interior of the table.
294
216
135
98
112
84
245
40
8890560
156800
55566
We start by factorizing the column products, to get , , and respectively. Since the second-column product isn’t divisible by 3, the second column must consist of only 1, 2, 4, 5, 7, and 8. The third column isn’t divisible by 4 or 5 so it can’t contain 4, 5, or 8; furthermore it contains only a single even number (2 or 6).
We can explicitly enumerate the possibilities for each row. For example for the row with product 84 we have
and so there are seven possibilities for this row. 7, 6, 2 doesn’t appear because the second column can’t contain a multiple of three.
This is actually enough to fill in a few entries, and we also can list all the possibilities for the remaining ones:
6, 7
7
6, 7
294
3, 6, 9
4, 8
3, 6, 9
216
3, 9
5
3, 9
135
2, 7
2, 7
2, 7
98
2, 4, 7, 8
2, 4, 7, 8
2, 7
112
2, 3, 4, 6, 7
2, 4, 7
2, 3, 6, 7
84
5, 7
5, 7
7
245
4, 5, 8
4, 5, 8
1, 2
40
8890560
156800
55566
Now the first column has product , so it must have a single 5 and three 7s. The remaining four entries have to multiply to so they must be two 9s and two 8s. That lets us complete the first column, because there is only two possible locations for a 9, two for an 8, and one for a 5. And knowing those first-column values allows us to complete various rows:
7
7
6
294
9
4, 8
3, 6
216
9
5
3
135
7
2, 7
2, 7
98
8
2, 7
2, 7
112
7
2, 4
3, 6
84
5
7
7
245
8
5
1
40
8890560
156800
55566
The third column only contains a single even number, which is enough to finish that column, and then work out the second column by arithmetic:
7
7
6
294
9
8
3
216
9
5
3
135
7
2
7
98
8
2
7
112
7
4
3
84
5
7
7
245
8
5
1
40
8890560
156800
55566
I was honestly surprised this puzzle was solvable – I didn’t believe there was enough information at first. I think it works out because the first-column product 8890560 is large enough that we can determine uniquely what the values in the column are and only have to put them in order; the third-column only having one even value works as well.
Also, I believe this puzzle was part of the MIT Mystery Hunt that took place this weekend (which I haven’t competed in in a Very Long Time). The Riddler column was named “Can You Hunt For The Mysterious Numbers?” and it says the puzzle was by Barbara Yew, and googling that “name” finds an MIT web page at yewlabs.mit.edu for something called “MYST2021: Maturing Young Scientific Theories: Expanding Reality & You” – the first letters spell “MYSTERY”.
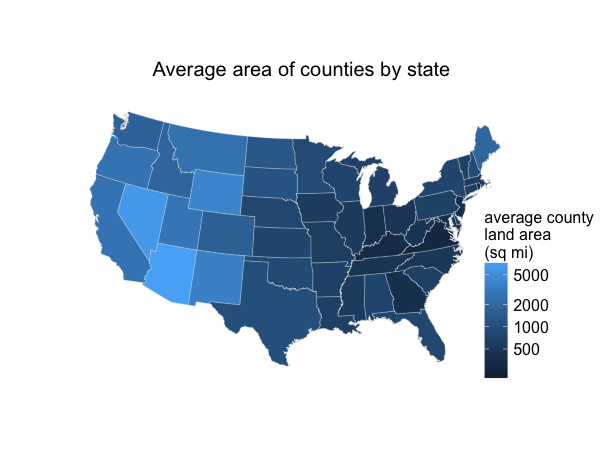
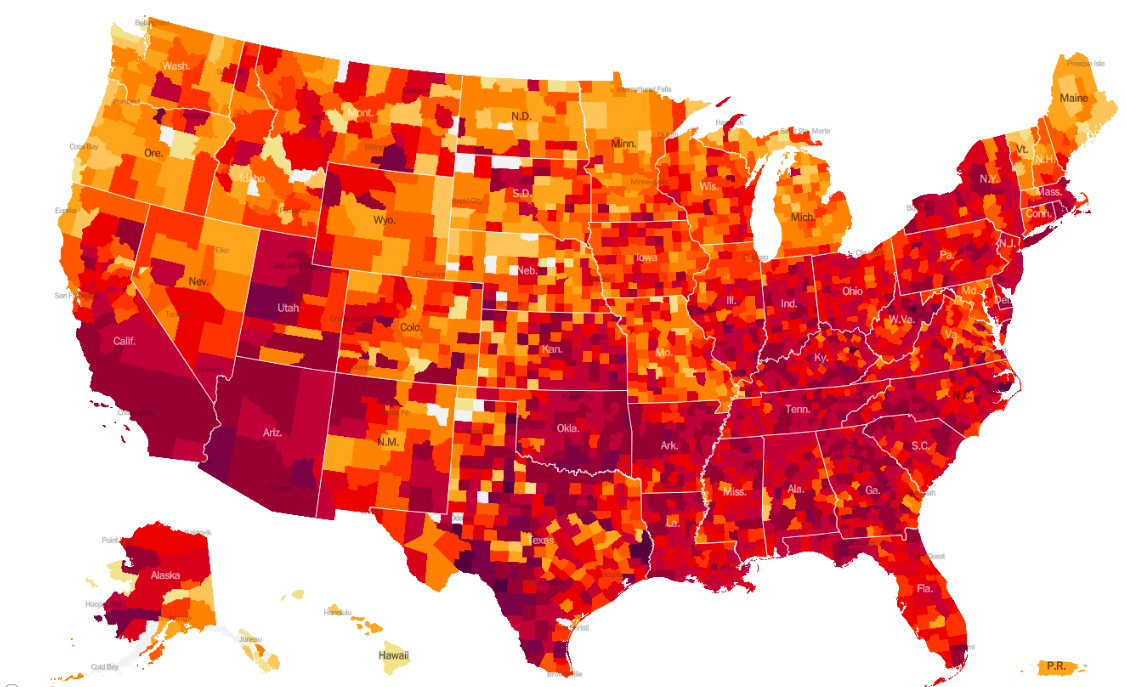
Washington Post map of coronavirus cases (per capita)
A friend of my wife’s pointed this out because Georgia jumps out at the eye on this map. My wife similarly noticed that Los Angeles did not look bad, recent reports of crisis there notwithstanding.
The reason is simple – Georgia has an unusually large number of counties for its size. We have 159 counties in 57,513 square miles, for an average area of 362 square miles. Compare Florida (67 counties, 53,625 square miles, average of 800 square miles per county) or Alabama (67 counties, 50,645 square miles, 756 square miles per county). There’s a belt of states stretching roughly north-northwest from Georgia on this map — Tennessee, Kentucky, Indiana, Ohio – that jumps out, and these are all among the states with the smallest average county size. Each county is represented by a circle with size proportional to its coronavirus case rate, so a state’s intensity of color is roughly (coronavirus case rate per capita) x (average county area). And average county area is larger in some parts of the countries than others, for historical reasons nicely expounded by Ed Stephan.
Average county areas by state, in square miles
The Post also has the same map with circle sizes proportional to the total number of cases per county. This, I think, looks much more like expected:
Washington Post map of coronavirus cases (total)
This fixes the issue in Los Angeles – it now has a very large circle, because Los Angeles County has ten million people. However this has the opposite problem – now low-population areas look relatively safe. For overall case rates I prefer a color-shaded map. The Post doesn’t have one, but the New York Times does. Darker/redder colors indicate higher case rates. (I’m old enough to remember when the color scale just went up to red, but not prescient enough to have captured those screen shots on a regular basis.)
New York Times map of coronavirus cases (per capita)
The Times also has a map with a circle for each county. This map isn’t directly comparable to The Washington Post map because it’s a map of the total number of cases; it uses larger circles, which has the effect of not making low-population-density states look totally unscathed by the coronavirus but at the cost of overlapping in high-population-density areas like coastal California or the Northeast corridor.
New York Times map of coronavirus cases (total)
At least to me, it seems natural to interpret the size of a circle as a raw number, and the color as a rate. Either one of the circle maps can be thought of as putting a little bit of red down near each case (recent cases in the WaPo map, all cases in the NYT). And so, if you squint, these maps don’t look all that different from population density maps, which Kieran Healy has called one of America’s ur-choropleths, because the variations in coronavirus rates are swamped by the variations in population density.
On Christmas Day I alluded to the fact that there are 364 gifts in the song “The Twelve Days of Christmas”. Is there a way to prove this that doesn’t require adding everything up?
As a reminder, on day k of Christmas (k = 1, 2, …, 12) the singer receives 1 of gift 1, 2 of gift 2, …, k of gift k. Christmas has 12 days. (Gift 1 is “a partridge in a pear tree”, gift 2 is “turtle doves”, and so on up to gift 12 which is “drummers drumming”, but this is irrelevant.)
So on day k there are total of gifts; this is . The total number of gifts received is therefore
and by the hockey-stick identity (sometimes also called the Christmas stocking identity) this is . The identity can be proven by induction, but I prefer a combinatorial proof. Consider the subsets of of size 3 and group them according to their largest element. Then there are sets whose largest element is , for each of .
This suggests another identity – what if we group according to the middle element of the subset instead? For example, there are 5 × 8 = 40 3-subsets of [14] whose middle element is 6; each one has one element chosen from 1, 2, …, 5 and one element chosen from 7, 8, …, 14. More generally there are k(13-k) 3-subsets of [14] with middle element k. Thus we have
In terms of the song, this is actually a natural way to count. is the number of gifts of type k, since such gifts get given on the last days – there are 12 total partridges in pear trees, 2 × 11 = 22 total turtle doves, 3 × 10 = 30 total calling birds, and so on until we get back down to 12 drummers drumming. (The most frequent gifts? 42 swans and 42 geese. Maybe that was the question.)
As you may have heard, there are runoff elections going on in Georgia today (January 5, 2021). You don’t need me to tell you this, and it’s probably too late, but if you live in Georgia, vote.
Also the presidential election in Georgia in 2020 was very close, as you may have heard: 49.47% for Biden, 49.24% for Trump. (The law does not allow for runoffs in presidential elections.)
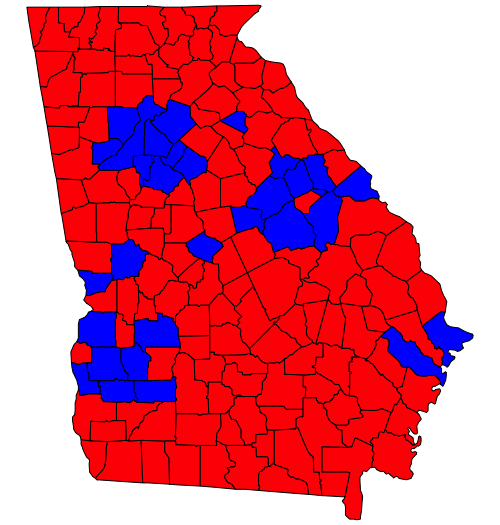
But here’s the surprising thing. Below are two maps of the state of Georgia. Can you spot the difference?
There is one county with a different winner in the two maps – Burke County, in the east-central part of the state. And Burke was won by Clinton in 2016 (left map), but by Trump in 2020 (right map). The only county that switched winners switched in the opposite direction of the state as a whole.
Furthermore, what if Georgia had an electoral college made up of counties?
Historically this is not entirely crazy; Georgia used to have something called the County Unit System for statewide primaries. In this system the largest eight counties were classified as “Urban”, the next-largest 30 counties were classified as “Town”, and the remaining 121 counties were classified as “Rural”; urban, town, and rural counties got 6, 4, and 2 votes respectively, awarded on a winner-take-all basis. This benefited rural candidates.
With current population statistics, the “urban” counties would be Fulton, Gwinnett, Cobb, DeKalb, Clayton, Chatham, Cherokee, and Forsyth. These are the county containing most of Atlanta, six suburban Atlanta counties, and the county containing Savannah; this category would better be called “suburban”.). Trump would have won 308 of the 410 county unit votes in 2020 – he won 2 of the 8 “urban” counties, 21 of the 30 “town” counties, and 106 of the 121 “rural” counties. In 2016 he would have won 310 of 410.
Unsurprisingly, a system this biased was found unconstitutional. But what if we had an electoral college? We can start with a simple calculation:
in 2020, Biden won 30 of 159 counties, making a total of 53.69% of the state’s population (5,643,569 in Biden counties, 4,867,562 in Trump counties)
in 2016, Clinton won 31 of 159 counties, making a total of 53.90% of the state’s population (5,666,008 to 4,845,123) – the difference being Burke, mentioned above.
This surprised me, but upon reflection, it makes sense – the red counties in Georgia are really red. But we all know a real electoral college gives smaller units undue influence. We can simulate that by adjusting the population of each county. In 2020 Biden won counties with 776,007 more people, but he won 99 fewer counties. So if we give each county eight thousand more “people” – analogous to the electoral votes that correspond to Senators – then Trump wins this state-level electoral college. Also in this world he’d be calling county commissioners instead of the Secretary of State.
But in any case we would not be talking about Georgia “flipping” from Republicans to Democrats between 2016 and 2020. The actual flipping was caused, mostly, by Atlanta suburbs moving to the left – but they happened to do so in a way where no counties crossed over. (The flipping of Gwinnett and Cobb, the two largest purely suburban counties, already happened between 2012 and 2016.). I haven’t explored this in-depth but it’s interesting to think about how an electoral college of counties distorts state-level results as a proxy for how an electoral college of states distorts national results.
In general we can view an integer as a polynomial – in the case of 2021, – evaluated at . Call this polynomial . Then its coefficient-reversal is where is the degree of the polynomial . For eample, if then we get the reversal Then we can show that is its own coefficient-reversal. It has degree . Upon substituting for and multiply by we get
$
which is itself.
Now if the coefficients of are all less than 10, we can interpret this as a fact about integers. The middle coefficient of is just the sum of the squares of the coefficients of – for example,
with middle coefficient .
For the proof that the sum of the squares is the largest coefficients, wave your hands and say “Cauchy-Schwarz”, then look at Proposition 10 of On Polynomial Pairs of Integers by Martianus Frederic Ezerman, Bertrand Meyer, and Patrick Sole.
Twelve circular muffins fit nicely on a circular plate.
Twelve muffins on a plate.
Yes, I know they’re not quite uniform in size. What do you want? My sous-chef is two years old. Also she was not helping but rather running around under the dining room table.
Anyway, this apparently is not the optimal packing – that is, the one that maximizes the ratio (muffin radius)/(plate radius), although it is a piece of the optimal packing in the infinite plane. You could fit slightly larger muffins if you packed them like this:
Optimal packing of twelve circles in a circle
Image from the Wikipedia article Circle packing in a circle. The proof is due to Ferenc Fodor, The Densest Packing of 12 Congruent Circles in a Circle, Beiträge zur Algebra und Geometrie, Contributions to Algebra and Geometry 41 (2000) ?, 401–409. The radius of the plate is 4.029… times the radius of the muffin. (This is where is the smallest positive root of .)
As it turns out, the packing I discovered isn’t all that far off from this constant. Let the radius of the muffin be 1, and draw triangles as below.
The center of the plate is at the center of the packing, which is the center of the red equilateral triangle. If this triangle has side 2, then the distance from its center to any of its vertices is . This is the length of the shortest side of the blue triangle.
The blue triangle therefore has sides of length and , with an angle of 150 degrees between them. The long side of the blue triangle, by the law of cosines, is given by
The distance from the center to the edge of the plate is then $latex\sqrt{28/3} + 1$, the length of the long side of the blue triangle plus the green line segment which is a single muffin radius. If you’re working this out in your head while watching the aforementioned sous-chef run around at the park, though, you wonder about the numerical value of this constant and think maybe you shouldn’t pull out your phone-calculator. Fortunately it’s easy to work out approximately: , and remembering for small this is very close to $3 (1 + 1/54) = 3 + 1/18 \approx 3.055$. So the radius of the (idealized) plate is about times the radius of the (idealized) muffin, not all that far off from the due to Fodor.

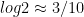

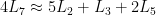






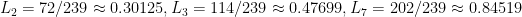
.
(a fundamental fact of musical temperament).

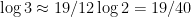
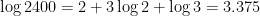
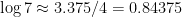
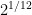


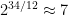

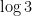











 . Euler proved
. Euler proved 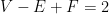 , which we’ll approximate as
, which we’ll approximate as  . Thus
. Thus  , or rearranging
, or rearranging 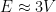 ; the number of edges (state borders) is about three times the number of states.
; the number of edges (state borders) is about three times the number of states.  ,
,  , and
, and  respectively. Since the second-column product isn’t divisible by 3, the second column must consist of only 1, 2, 4, 5, 7, and 8. The third column isn’t divisible by 4 or 5 so it can’t contain 4, 5, or 8; furthermore it contains only a single even number (2 or 6).
respectively. Since the second-column product isn’t divisible by 3, the second column must consist of only 1, 2, 4, 5, 7, and 8. The third column isn’t divisible by 4 or 5 so it can’t contain 4, 5, or 8; furthermore it contains only a single even number (2 or 6). so they must be two 9s and two 8s. That lets us complete the first column, because there is only two possible locations for a 9, two for an 8, and one for a 5. And knowing those first-column values allows us to complete various rows:
so they must be two 9s and two 8s. That lets us complete the first column, because there is only two possible locations for a 9, two for an 8, and one for a 5. And knowing those first-column values allows us to complete various rows: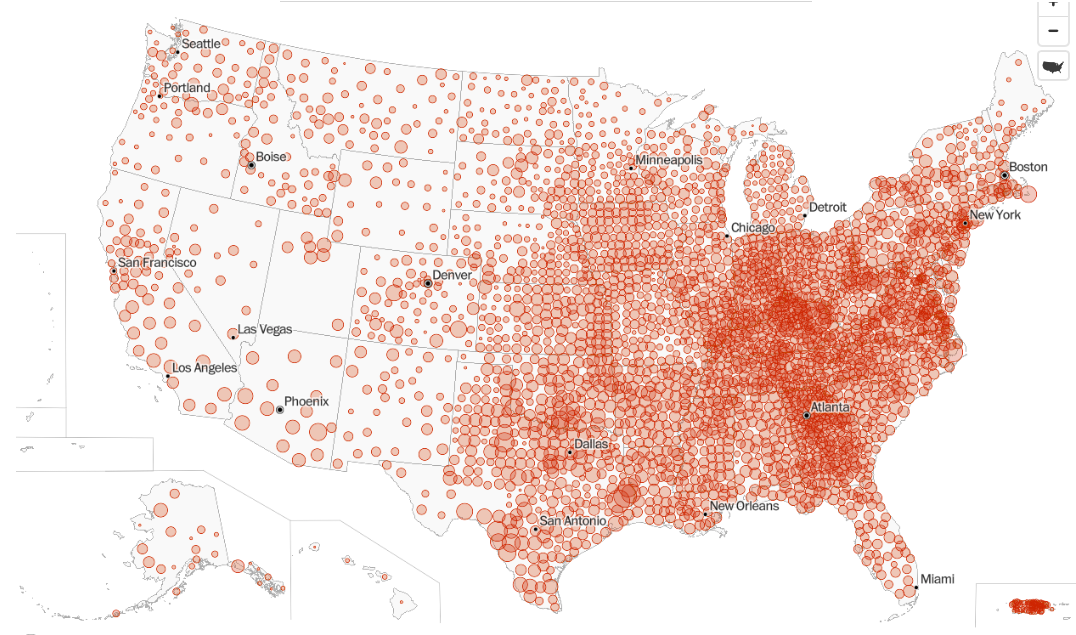



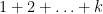 gifts; this is
gifts; this is 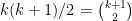 . The total number of gifts received is therefore
. The total number of gifts received is therefore
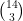 . The identity can be proven by induction, but I prefer a combinatorial proof. Consider the subsets of
. The identity can be proven by induction, but I prefer a combinatorial proof. Consider the subsets of  of size 3 and group them according to their largest element. Then there are
of size 3 and group them according to their largest element. Then there are 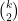 sets whose largest element is
sets whose largest element is 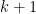 , for each of
, for each of  .
.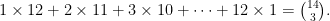
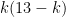 is the number of gifts of type k, since such gifts get given on the last
is the number of gifts of type k, since such gifts get given on the last  days – there are 12 total partridges in pear trees, 2 × 11 = 22 total turtle doves, 3 × 10 = 30 total calling birds, and so on until we get back down to 12 drummers drumming. (The most frequent gifts? 42 swans and 42 geese. Maybe that was the question.)
days – there are 12 total partridges in pear trees, 2 × 11 = 22 total turtle doves, 3 × 10 = 30 total calling birds, and so on until we get back down to 12 drummers drumming. (The most frequent gifts? 42 swans and 42 geese. Maybe that was the question.)
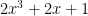 – evaluated at
– evaluated at 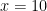 . Call this polynomial
. Call this polynomial  . Then its coefficient-reversal is
. Then its coefficient-reversal is 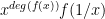 where
where 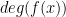 is the degree of the polynomial
is the degree of the polynomial  then we get the reversal
then we get the reversal 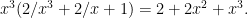 Then we can show that
Then we can show that  is its own coefficient-reversal. It has degree
is its own coefficient-reversal. It has degree 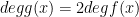 . Upon substituting
. Upon substituting 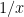 for
for  and multiply by
and multiply by 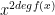 we get
we get 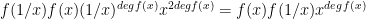 $
$ itself.
itself. 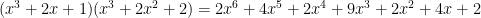
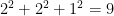 .
.  is prime when evaluated at 0, 1, 2, …, 39, and
is prime when evaluated at 0, 1, 2, …, 39, and 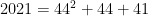 .
.


 where
where  is the smallest positive root of
is the smallest positive root of  .)
.)
 . This is the length of the shortest side of the blue triangle.
. This is the length of the shortest side of the blue triangle. , with an angle of 150 degrees between them. The long side of the blue triangle, by the law of cosines, is given by
, with an angle of 150 degrees between them. The long side of the blue triangle, by the law of cosines, is given by
 , and remembering
, and remembering  for small
for small 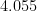 times the radius of the (idealized) muffin, not all that far off from the
times the radius of the (idealized) muffin, not all that far off from the  due to Fodor.
due to Fodor. 
{kind=link}