Tom Tango, while writing about lineup construction in baseball, pointed out that batters batting closer to the top of the batting order have a greater chance of setting records that are based on counting something – for example, Chris Davis’ chase for 62 home runs. (It’s interesting that enough people see Roger Maris’ 61 as the “real” record that 62 is a big deal.) He observes that over a 162-game season, each slot further down in the batting order (of 9) means 18 fewer plate appearances.
Implicitly this means that every slot in the batting order is equally likely to end the game — that is, that the number of plate appearances for a team in a game, mod 9, is uniformly distributed over {0, 1, …, 8}.
Can we check this? There are two ways to check it:
- 1. find the number of plate appearances in every game. This is boring.
- 2. come up with a model for the number of plate appearances in a game and see what comes out. This is exciting.
We need some basic statistics. From baseball-reference.com’s 2012 MLB season page on batting, we can find out that last year there were 184,179 plate appearances. From the season pitching page we learn there were 43,355 and a third innings pitched; at three outs per inning that’s 130,066 outs. So 70.6% of plate appearances include an out; 29.4% don’t. (I’m simplifying here in not accounting for double or triple plays, which come on plate appearances with more than one out.)
The question then boils down to: how many plate appearances does it take to get 27 outs? (Again, I’m simplifying: sometimes the home team doesn’t bat in the bottom of the ninth, there are extra innings, about which you should read this paper by Darren Glass and Philip Lowry, and so on.) That’s given by one parameterization of the negative binomial distribution. Let’s have the following model of baseball:
- The game consists of a series of plate appearances.
- Assume that any plate appearance has probability 1-p = 0.294 of no outs, and p = 0.706 of one out.
- When you get 27 outs, the game is over.
- Nobody keeps score. This isn’t real baseball.
Then what’s the probability that the game ends on the nth plate appearance, for any 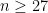 ? Among the first n – 1 plate appearances there must be exactly 26 outs; the probability of this happening is
? Among the first n – 1 plate appearances there must be exactly 26 outs; the probability of this happening is  . Then the last plate appearance must be an out, which happens with probability p. So the probability of this game ending in
. Then the last plate appearance must be an out, which happens with probability p. So the probability of this game ending in  plate appearances is
plate appearances is
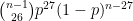 .
.
(Incidentally, if we set  we get this model’s estimated probability of a perfect game. It’s (0.706)27, which is about one per 12,000 team-games. There have been 21 perfect games since 1900 and about 360,000 total team-games since 1900, for one in 17,000 or so – roughly in the right neighborhood, at least, for such a crude model.)
we get this model’s estimated probability of a perfect game. It’s (0.706)27, which is about one per 12,000 team-games. There have been 21 perfect games since 1900 and about 360,000 total team-games since 1900, for one in 17,000 or so – roughly in the right neighborhood, at least, for such a crude model.)
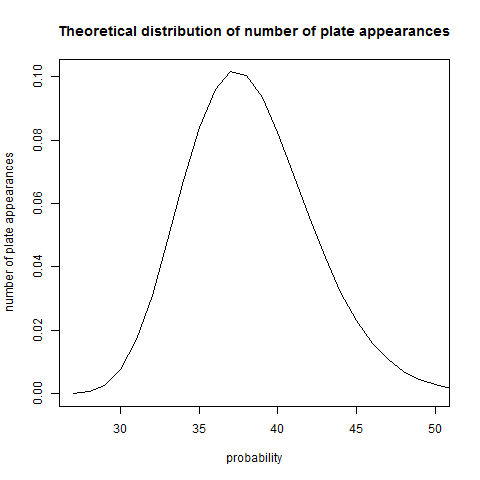
It turns out that a baseball game is not quite long enough to get the distribution to totally equalize. Here’s a plot of the distribution of the number of plate appearances per game:
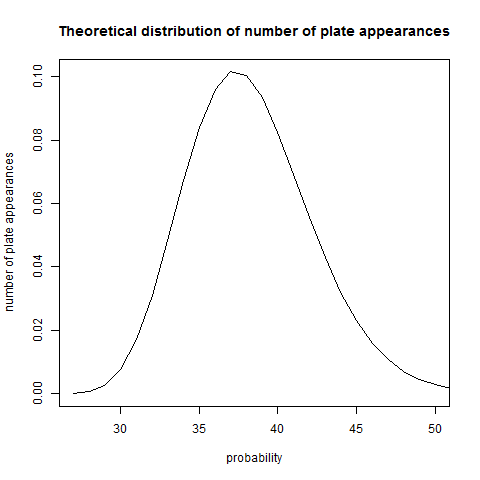
The distribution is not incredibly wide – the standard deivation is 3.99. Is this wide enough to get uniformity mod 9? Not quite. In the plot below, the red, green, and blue lines represent the probability of the game ending in the fourth, fifth, and sixth times through the order (28-36, 37-45, and 46-54 plate appearances, respectively), with the batter in the slot indicated on the x axis. The black line is the overall probability of ending on a given slot – the sum of the red, green, and blue lines, plus some other lines that are suppressed (games with 27 plate appearances, or 54 or more) that are graphically indistinguishable from zero.

The probability of the game ending with a batter in the kth slot in the order is given by the table below:
| slot number |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| prrobability |
.118 |
.114 |
.108 |
.104 |
.103 |
.106 |
.111 |
.116 |
.120 |
So the distribution is visibly not flat – but flat enough for Tango’s practical insight to make sense. Maybe moving someone up is expected to get them 17 extra plate appearances, or 19, instead of 18, depending on the slot. But the point still stands. In practice the distribution of the final slot is probably even flatter than it appears here – the distribution of the number of plate appearances should be wider, since teams differ in skill, there are extra-inning games or games in which the home team doesn’t bat in the ninth, and so on.

 , where
, where  . This is about
. This is about  , or one in thirty trillion. (The probably that five or more balls will be hit to me is orders of magnitude lower than that.)
, or one in thirty trillion. (The probably that five or more balls will be hit to me is orders of magnitude lower than that.) , which is about one in two million. So this should have happened 35 to 40 times last year – it’s just that most of the people who it happened to didn’t bother telling anybody! (Other than their friends, who probably didn’t believe them.)
, which is about one in two million. So this should have happened 35 to 40 times last year – it’s just that most of the people who it happened to didn’t bother telling anybody! (Other than their friends, who probably didn’t believe them.) distinct riffle shuffles of n cards. For example, consider a five-card deck, which is initially in the order 1, 2, 3, 4, 5. Then a riffle shuffle consists of:
distinct riffle shuffles of n cards. For example, consider a five-card deck, which is initially in the order 1, 2, 3, 4, 5. Then a riffle shuffle consists of: possible ways to make a permutation from this – we decide which two slots to put the 4 and the 5 in, and then everything else is forced. For example if we decide that 4 and 5 will go in the second and fourth positions, we must get 14253. In general if we have k cards in the left-hand pile and
possible ways to make a permutation from this – we decide which two slots to put the 4 and the 5 in, and then everything else is forced. For example if we decide that 4 and 5 will go in the second and fourth positions, we must get 14253. In general if we have k cards in the left-hand pile and 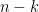 cards in the right-hand pile, we have $\latex n \choose k$ possible shuffles. Furthermore we can decompose any one of these permutations into two “rising sequences” in exactly one way, so it can come from exactly one cut — with a single exception. That exception is the identity permutation
cards in the right-hand pile, we have $\latex n \choose k$ possible shuffles. Furthermore we can decompose any one of these permutations into two “rising sequences” in exactly one way, so it can come from exactly one cut — with a single exception. That exception is the identity permutation  , which we can obtain from any of the n+1 possible cuts — so we must subtract n for the duplications. (If you put probabilities on this it becomes the
, which we can obtain from any of the n+1 possible cuts — so we must subtract n for the duplications. (If you put probabilities on this it becomes the 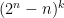 possible results. There will actually be less, because there are relations among the permutation subgroup generated by the riffle shuffles. (In less fancy language, there are sequences of different shuffles which give the same result. It’s the
possible results. There will actually be less, because there are relations among the permutation subgroup generated by the riffle shuffles. (In less fancy language, there are sequences of different shuffles which give the same result. It’s the 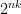 to make the math easier. Now, there are
to make the math easier. Now, there are 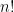 permutations; this is greater than
permutations; this is greater than  by a standard bound. So just in order to have
by a standard bound. So just in order to have  , or, taking nth roots of both sides,
, or, taking nth roots of both sides, 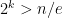 . Taking base-2 logs, we get
. Taking base-2 logs, we get  .
.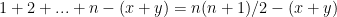 . Setting these equal and rearranging gives
. Setting these equal and rearranging gives
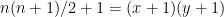 .
.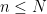 which are solutions to the problem — that is, where xy equals the sum of all the integers up to n except for x and y. The first few solutions are:
which are solutions to the problem — that is, where xy equals the sum of all the integers up to n except for x and y. The first few solutions are: and
and  are both solutions. In this case $latex n(n+1)/2 + 1 = 52976 = 24 \times 7 \times 11 \times 43$, from which 52976 has (5)(2)(2)(2) = 40 factors. A typical number of this size has about
are both solutions. In this case $latex n(n+1)/2 + 1 = 52976 = 24 \times 7 \times 11 \times 43$, from which 52976 has (5)(2)(2)(2) = 40 factors. A typical number of this size has about  factors. This abundance of factors makes it more likely that 52976 would have two factorizations of the sort we’re looking for. And in fact
factors. This abundance of factors makes it more likely that 52976 would have two factorizations of the sort we’re looking for. And in fact 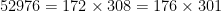 .
.