The Open Syllabus Project has collected syllabuses1 from about a million college classes. From this they’ve created the Open Syllabus Explorer.
It’s generally focused on listing which texts occur in syllabi. This ends up meaning that it’s mostly useful for humanities classes, since they tend to assign a larger number of texts. I remember my grad school oral exams, where there were perhaps four books I was studying from; there were friends of mine in the humanities that would have, say, 50 books.
That being said, it’s still interesting to know that people who assign Stanley’s Enumerative Combinatorics also assign Wilf’s generatingfunctionology. And, somewhat more confusingly, Rudin’s Real and Complex Analysis – which makes me suspect that perhaps some lists of canonical math texts in a variety of subjects got caught in the dragnet.
An analogue of this for more technical subjects, where there are many books covering similar material and where there are fewer texts per course, would examine the portions of the books which are covered. Which subjects are seen as essential, and which ones are not? Many textbooks include a bit in the introduction that can be paraphrased as “my book is too long for one course, I know, so here are some one-course subsets of it” – but which of those susbets actually get used? This would require parsing the syllabi, and is perhaps feasible (and maybe the folks at the OSP are thinking about it). This is very much the sort of thing I would have liked to see when I was planning new courses, and on a hard drive that no longer works I’m pretty sure I have some files with lists of “professor X, in semester Y, covered chapters A, B, and C of the textbook”.
(Via NYT.)
1. My wife, a classics major, informs me that that’s the right plural, because “syllabus” is not of the declension that pluralizes by taking “-us” to “-i”. Interestingly, the NYT article uses “syllabuses” but the OSP’s page uses “syllabi”.
 th percentile of the predicted distribution of accumulation for
th percentile of the predicted distribution of accumulation for  ;
; and it should take
and it should take  steps to get from
steps to get from  where
where  .
. . (The constant is different there; that’s because Lagarias goes directly from
. (The constant is different there; that’s because Lagarias goes directly from  to
to  if
if  to be the number of iterations in this process needed to get to 1. For example look at the trajectory for 7 above; it takes 16 iterations to get to 1, so
to be the number of iterations in this process needed to get to 1. For example look at the trajectory for 7 above; it takes 16 iterations to get to 1, so  . Similarly for example
. Similarly for example  (the trajectory is 4, 2, 1) and
(the trajectory is 4, 2, 1) and  (the trajectory is 6, 3, 10, 5, 16, 8, 4, 2, 1). This is the sequence
(the trajectory is 6, 3, 10, 5, 16, 8, 4, 2, 1). This is the sequence  . But since “most” numbers less than $\latex n$ have their logarithms near $\latex \log n$, that sum can be approximated as just
. But since “most” numbers less than $\latex n$ have their logarithms near $\latex \log n$, that sum can be approximated as just  or $\latex C \log n$.
or $\latex C \log n$. )
)
 and the blue curve is
and the blue curve is  . But it’s not like you’d expect asymptotic behavior to kick in by 5000 anyway.
. But it’s not like you’d expect asymptotic behavior to kick in by 5000 anyway.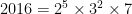 .
.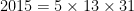 .
.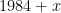 ? These are just the factors of
? These are just the factors of 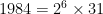 .
.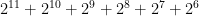
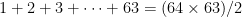

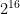 , which you can download from
, which you can download from  and
and 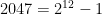 inclusive.
inclusive.